Directory
Helpful Links
To Address Next Meeting
- ...
Meeting Notes
2021-06-10
Agenda:
2021-06-03
Attendees: Burke, Allan, Bashir, Mike S, Suruchi, Tendo, Grace P, Joseph, Jen, Daniel
Updates:
- Suruchi worked on inconsistent naming of parameters between streaming and batch pipeline
- Alan focused on getting 5 sample PEPFAR indicators working
- Alan & Bashir to try running at Ampath over the weekend; plan for next week is to get datawarehouse batch ready with sample data from the last 3 months and test against the indicator library
Bashir proposal: Skip thursday calls if nothing to discuss
- Check for agenda items on Slack on Wednesdays. If no agenda items or only updates, then Thursday call can be canceled. (Bashir to own)
- https://om.rs/aesnotes You can enter agenda items here
Resources for demo data
- PIH viral load report: https://github.com/PIH/openmrs-config-pihemr/blob/master/configuration/pih/petl/jobs/hiv/viral_load/
- Indicators: Analytics Engine (including ETL and reporting improvement)
https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics/projects/1
2021-05-27: Memory Issue & Streaming Updates; Q&A
Attendees: Suruchi, Bashir, Tendo, Mike, Daniel, Grace P, Burke, Amos Regrets: Alan
Updates:
Bashir: (1) Memory issue being addressed by writing parquet files quickly after fetching resources → Need to test at AMPATH over a weekend. (2) Consolidating streaming pipeline. Any new resources that come from EMR are handled by streaming branch; at same time in parallel, starts fetching from historical resources.
Questions:
- Will warehouse contain flat files, that people with MySQL experience could query?
- Data are pulled into the warehouse as FHIR resources into a SQL on FHIR schema
- The SQL on FHIR data are then written into Parquet files
- Are updates to the warehouse incremental, so when a new record comes in things are auto updated?
- The analytics engine is being designed to support both batch mode (to bootstrap or to re-generate the data warehouse) and incremental updates (as typical use case of streaming changes to the warehouse in near real-time)
- There is a notion of "pages" where resources are loaded in small batches before being flushed. The paging can be configured based on time (e.g., flushing each minute, each hour, each day). Larger pages can improve performance at the cost of more memory and a longer delay in data getting into the warehouse.
- Can the solution work in an offline mode - can it run at a facility without internet connection, so evaluation staff can still pick data from the warehouse and process further?
- Yes. The analytics engine is designed to run against an instance of OpenMRS and doesn't require internet access to transform the data.
Review of PIH Examples
- https://github.com/PIH/openmrs-config-pihemr/tree/master/configuration/pih/petl/jobs
https://github.com/PIH/openmrs-config-pihemr/blob/master/configuration/pih/petl/jobs/hiv/viral_load/target.sql 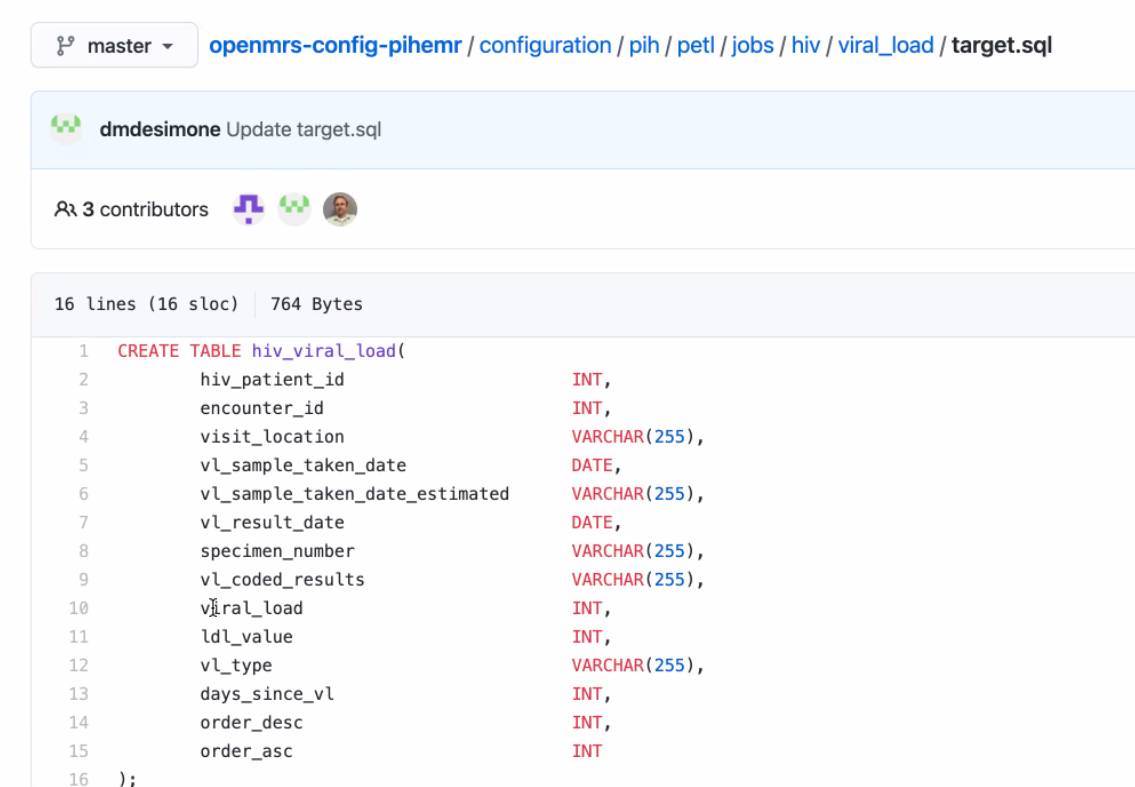
2021-05-20:
Attendees: Amos Laboso, Burke, Bashir, Ian, Jennifer, Grace, Mike, Suruchi, Moses
Regrets: Alan
Summary:
Updates:
Bashir: FHIR resources being kept in memory for too long due to local runner. Bug caused by OMRS modelling. Thinking we shouldn't pursue since cluster use-case doesn't seem prevalent. Deciding whether to run through just local or provide option for either Distributed vs local system
Using the FHIR→ parquet files approach s consuming a lot of memory and slowing us down b/c we're running into erros and memory issues. Needing to cluster by picking from OMRS and putting into parquet files is not a work around. Trying to stay cloud ready as long as we can function well on a single server. h
Smaller sites & offline
2021-05-13:
Recording: https://iu.mediaspace.kaltura.com/media/t/1_6m0e3ubn
- Proposal: Call time change to 1 hr later? (switch with MFE squad)
- Bashir would have a conflict on some weeks
- Updates
- Ampath: Active & historical datasets. Not able to run historical: issues running out of memory. Solution proposal: ___
- Bug: Loading FHIR resources many times - haven't been able to reproduce
- Time based disaggregation into indicator
- Could we demo using engine to create a flattened file?
- General approach is (1) OMRS → FHIR warehouse. (2) Create a library on top of the FHIR data warehouse so people can query easily. Part of this would include producing the flat tables.
- Would create views on FHIR data warehouse; those come from the library. (Dependent on performance of those views.)
- Goals
- Able to run pipelines at AMPATH scale.
- Show the libraries are performant at AMPATH scale. → End Goal this Quarter: System that can supplement current AMPATH ETL/reporting pipeline (start supporting production-level reporting needs for AMPATH)
- How can we get other implementations involved/interested in Analytics Engine development?
- Knowing use cases / pain points would be very helpful for analytics engine work at this point
- PIH has a working solution, but would like a solution that...
- Provides consistency across different implementations (all have different reporting solutions)
- Avoid having to rebuild warehouse tables from scratch
- The analytics engine can work in batch or incremental mode. Batch is probably better when it performs sufficiently for business needs. Streaming/incremental mode introduces complexity.
- The analytics engine is using FHIR to standardize clinical data. Not all data within OpenMRS will fit into the FHIR model. Currently, the Analytics Engine team is prioritizing FHIR schema data for now.
- Will plan on discussing technical approach choices on next Tuesday's call
2021-05-06:
- Updates
- Ampath: Deployed!! Saturday doing data extraction, now focusing on indicator generation for PEPFAR indicators. Then should be able to achieve one of the main goals for this quarter.
- Organizing resources in datawarehouse
- Incremental generation of parquet files for resources + debugging
- Ampath: Deployed!! Saturday doing data extraction, now focusing on indicator generation for PEPFAR indicators. Then should be able to achieve one of the main goals for this quarter.
- Reporting Module Project Proposal
- Will reach out on Talk or in Slack
- ETL / Flattening update from PIH/Mike - "if we were to create a flat table, how would that look"
- Mike Seaton demonstrated how PIH is using combinations of YML and SQL files to ETL data from MySQL into a data warehouse (SQL Server)
- https://github.com/PIH/openmrs-config-pihemr
- Primary focus is to get data into flattened format so data analysts can understand and use it
- Mike Seaton demonstrated how PIH is using combinations of YML and SQL files to ETL data from MySQL into a data warehouse (SQL Server)
2021-04-29:
Want to hear from other people; open new perspective. Without having a dedicated Product Manager, need reps from other teams to bring their problems and efforts to address. Otherwise without PM, dev leads can't take on burden of going around and understanding others' problems.
- PIH
- Using YAML and SQL to define exports that pull data from OpenMRS to a flat table that PowerBI can use
- OHRI - UCSF
- COVID
Ampath run updates
Dev updates
...
AES has (to date) been the combination of three organizations/projects working together on an analytics engine to meet their specific needs:
- AMPATH reporting needs
- PLIR needs
- Haiti SHR needs
MVP
- System that can replace AMPATH's ETL and reporting framework
TODO: Mike to create an example of "if we were to create a flat table, how would that look"
2021-04-15: Squad Call
https://iu.mediaspace.kaltura.com/media/t/1_80xjwir1
Attendees: Debbie, Bashir, Daniel, David, Burke, Ian, Jen, Allan, Natalie, Tendo, aparna, Mike S, Naman, Mozzy
Welcome from PIH: Natalie, Debbie, David, Mike
- M&E team get a spreadsheet emailed from Jet.
- Issues with de-duplicating patients.
- Datawarehouse created for Malawi being redone.
- Recent projects have taken different approach - M&E teams analyze the KPI requirements, adn then design the SQL tables they'd want, then they do an ETL table to have exactly what they'd want for PEPFAR reporting and MCH reporting.
- Past approach was too complicated; didn't promote data use.
Details of past situation
- Previously you'd go into OMRS and you'd export and download an Excel spreadsheet. Exports started to be more and more wrong. Wrong concept, or new concepts added that weren't reflected in exports; people lost trust. To see how things were calculated was very opaque.
- 7 health facilities into one DB; another 7 into another DB; then the 2 DBs merged together in reporting (which is done on the production server of one of those sets b/c there's not a 3rd server, but a new one is being set up for reporting.)
- They were hoping to set up on Jet but seems proprietary, expensive, and old; starting hosting clinical data in this 2 yrs ago. Started pulling in raw (or flattened?) tables - patient tables, enrollment tables. Pull those into the Jet DW
- COVID started and they also weren't able to travel to sites to do training on Jet.
- Switched back to Pentaho & MySQL - used before, open source. Hired 2 new people on Malawi team who were comfortable with that tool and could build their own warehouse in there.
- Main need: 1 table per form. So however concepts organized into a form, needs to make sense as a table unit. Each form - 1 table.
- Would like to add things like enrollment, statuses.
- Why? Forms = intuitive unit; indicator calc usually like obs at last visit,
- 80% Doesn't usually require cross-visit info
- KEMR similar - created a table to automate 1 tbl per form
- Previous tables were extremely wide because it was all the questions we'd ever asked. Would cut that up into multiple tables.
- PowerBI dashboards will be connected to these 1-form tables.
- Volume: Malawi: 50,000pts, a few million obs. Haiti: 500,000-1m, 10's millions of encounters, x4-5 for obs.
- Time: 5-10 mins to run. But in some other servers it's longer and a barrier, e.g. over an hour and increasing by the day - so that's why they're moving away from full DB flattening to one that's more targeted based on what data you're looking for.
- Ultimate Goal: Anything that makes it easier, esp. for local M&E people, to get their hands on the data and make the reports, is great. Easier access, and automation that reduces the workload of local M&E.
Overview:
- Targeting Ampath, because: 10's of clinics supported in a central DB. Has a complicated ETL system that doesn't scale very well, complex so few people understand it, and where the data came from is too opaque to instill sense of trust; want to replace it. M&E team needs flattened data. Want to flatten data into analytical tables that can be converted into tables like excel that they can run their own reports on.
- next, want to try supporting someone who is distributed, and then centralize the data.
- Design goals:
- Easy to use on a single machine/laptop. Whole system can be run on signle machine.
- ETL part: 2 modes of operations, batch mode and streaming mode.
- Reporting part:
Questions
- if you have any other questions for what might be useful for an M&E/Analytics person please email me at nprice@pih.org
- What are the best ways forward for PIH to try this and apply to some of their mor challenging use cases? E.g. local M&E teams not showing analytics of things happening over time
- Follow up to figure out how to create the FHIR resources...
2021-04-01: Squad Call
Attendees: Bashir, Moses, Tendo, Burke, Daniel Ian
Regrets: Allan, JJ, Grace P, Cliff
- Bashir: working on date-based filtering, as a way to get data only for "active" patients within a date range (e.g., all data for "active" patients within the past year)
- Given a list of resources and a date range, we pull all dated resources within the date range
- For all pulled resources that refer to a patient, we pull all data for each patient
- Moses: working on a blocker, inability to pull person and patient resources for the same individual in the same run (#144)
- Tendo: working on implementing media resource, working through complex handler
- Cliff (in absentia) working on running system via docker command
- Skipping meeting next week due to OpenMRS 2021 Spring ShowCase
2021-03-25: Squad Call
Attendees: Bashir, Allan, Cliff, Daniel, Ian, JJ, Allan, Ivan N, Willa, Grace P
Recording: https://iu.mediaspace.kaltura.com/media/t/1_msvydoso
Summary:
1. Decision: New design for date-based fetching in the batch pipeline, based on active period (for each patient "active" in care, all the resources will be extracted). We defined an "active" period (the last year), and break down the fetch into 2 parts: (1) any obs from the last year, then (2) for each patient with a history in the active period, all of their history will be downloaded. Why: Avoids search query time-out problems.
2. Later: Add ability to retrospectively extract resources back in time (re-run pipleline for any time period) in order to update your datawarehouse.
Updates:
- Bashir: Close to fix for memory issue; working on date-based
- Allan: Trying to finalize orchestration of indicator calculation. Implementing using docker & docker compose. Streaming mode.
- Antony (regrets): Working on list of indicators that need baseline data.
- Cliff: Streaming mode script. Refactoring in batch mode.
- Mike: Experimenting with approach, more updates next week.
Current plan for implementing date-based fetching: Getting the data when you need it, not all at once.
- Implemented on FHIR search base path. 2 modes for batch: pipeline JDVC mode, and FHIR search base.
- First step allows qualifying "I need last year"
- List of pts who've had >=1 obs in last year
- Second download, we download all of the resources going back.
- This will avoid the search query time-out problem we ran into in past. Idea is to download small batches in parallel.
Concern raised by JJ:
Approach needs to be able to handle queries that involve all patients, and need to be able to prove findings (i.e. can't simply use an aggregate deduction model, because you can't show "here are the exact patients" if someone needs to confirm your numbers are correct).
2021-03-18: Squad Call
Attendees: Bashir, Allan, Mike Seaton, Grace P, Christina, Burke, Cliff, Daniel, Ian, Ivan N
Recording: https://iu.mediaspace.kaltura.com/media/t/1_qj4xzv9t
Summary: What do we do with big databases with batch mode (where it's not feasible to download everything as FHIR resources or it will take a very long time)?
Two approaches came out to address the above problem:
1. First approach is limit by date (last week's discussion focused on this)
2. Second approach is to limit by patient cohort (focused on this today; idea is you'd limit queries based on patient instead of based on date, e.g. "Fetch everything for a cohort of patients") → We think this will be a better approach to try out moving forward.
Updates:
- PIH looking for Analytics Solutions, Mike's reviewed ReadMe, interested in trying out. Next: ______
- Bashir: Decision to do date-based separation of parquet files. Planning to go back to the FHIR-based search approach.
- Google contrib Omar: another 20%er from Google who is contributing PRs. Added JDBC mode to E2E tests.
- Google contrib William: still doing ReadMe changes/refactoring and move dev-related things under the doc directory.
- Allan: Instead of using distributed mode, use local mode.
- Cliff: Looking at datawarehousing, & issue of fhir resources in DW.
- Mozzy: Bug fixes so it can be used w/ Bahmni.
Discussion of Challenges:
FHIR structure isn't causing delays, but the conversion of resources into FHIR structure is slowing things down. TODO: Ian to look into improvements that could be made in FHIR module.
2021-03-11: Squad Call
Attendees: Bashir, Antony, Daniel, Grace, Allan, Moses, Tendo, Ojwang, Ken, Jen
Recording: https://iu.mediaspace.kaltura.com/media/t/1_lskh65vm
Summary: Discussed memory problems & performance in Ampath example. Direction we're taking for Ampath: To divide DW based on date dimension. For most of the resources, we don't generate for the whole time, just the last 1-2 yrs. Then we need to support special set of codes, where we generate the obs just for those codes. The set of those obs is much smaller.
- Work Update
- Bashir: Code reviews & investigation of memory issue. Added JSON feature into pipeline since it was helpful w/ debugging.
- Allan: Working to dockerize streaming mode, how to register indicator generation.
- Suggestion from Bashir: Adding more indicator calculation logic would be great.
- Moses: Upcoming PR w/ bug fixes
- Sending too many requests: had been looking at moving to using POST but fetching 100 resources at a time takes a few seconds, and can flood MySQL and OMRS, so doesn't see much value in fetching 1000's resources at a time on a local machine. 90 resources was actually faster.
- 2 other new contributors:
- Engineers at Google can spend 20% time on other projects. Posted some projects a few weeks ago related to this squad.
- Omar working on adding JDBC mode to batch end-to-end test
- William working on documentation fixes; trying to keep README user-centric rather than dev-centric. Anything dev-centric goes to separate files.
- Engineers at Google can spend 20% time on other projects. Posted some projects a few weeks ago related to this squad.
- Memory Issue with fetching encounter resources at AMPATH
- Compile list of IDs to be fetched; send 100-resource-request at a time to OMRS; convert those into Avro, and write into a parquet file. So because there is no shuffle anywhere, should continuously work regardless of the size of DB, and the memory requirement shouldn't increase.
- Investigated:
2021-03-04: Squad Call
Recording: https://iu.mediaspace.kaltura.com/media/t/1_yyg2els7
Attendees: Allan, Bashir, Moses, Antony, Cliff, Daniel, Ian, Jen, Ken, Sri Maurya, Steven Wanyee
Updates
- Bashir:
- Coverage reports added to repo.
- Bug identifying, & fix is out (not generating parquet; adding a flag to set number of shards)
- Fetching initial id list: Realized this isn't being slowed down by FHIR search or JDVC mode. Turns out it was the generation of Parquet - causing order of magnitude slower.
- Beam: Distributed pipeline environment. It's deciding how many segments for the output file to generate. Seems like an issue with Beam, Bashir to report to Beam.
- More Google people expected to start contributing eventually - up to 20 people
- Allan
- Moses
- Antony to follow up with Bashir and Moses to setup on machine & to join Tuesday check-ins
- Apparently there has been some testing of CQL against large data sets with Spark
- Intro from Maurya Kummamuru: Extracting OMRS data w FHIR to perform CQL queries against it. Demo coming at FHIR squad next week Tuesday.
2021-02-25: Squad Call
Recording: https://iu.mediaspace.kaltura.com/media/t/1_fa0o9440
Updates: Substantial bug fixing needed for Ampath pipeline pilot; 2.5hrs for table with 800,000 patients too slow.
2021-02-18: Squad call
Recording: https://iu.mediaspace.kaltura.com/media/t/1_m0rqigrl
Attendees: Burke, Tendo, Ian, Bashir, Amos Laboso, Cliff, Daniel, Jen, Grace, Allan, Mozzy, Sharif
Updates: Focus atm is on preparing for Ampath pipeline pilot release.
2021-01-28: Squad call
Recording: https://iu.mediaspace.kaltura.com/media/1_glpg4zts
2021-01-21: Data Simulation Engine demo, Random Trended Lab Data Generation demo, and How to Use Spark demo
Recording: https://iu.mediaspace.kaltura.com/media/1_q8wr0m9h
Attendees: Burke, Bashir, Antony, Cliff, Daniel, Ian, Jacinta, JJ, Juliet, Justin Tansuwan, Piotr, Steven Wanyee, Grace
- Data Simulation Engine: Ian demo
- Engine that generates random patients and random VL values for them. E.g. simulation that runs for a time range of 5 years, to show people coming in and getting lab tests over the course of 5 years of visits:
- Built using data like LTFU, % of pts with a suppressed VL
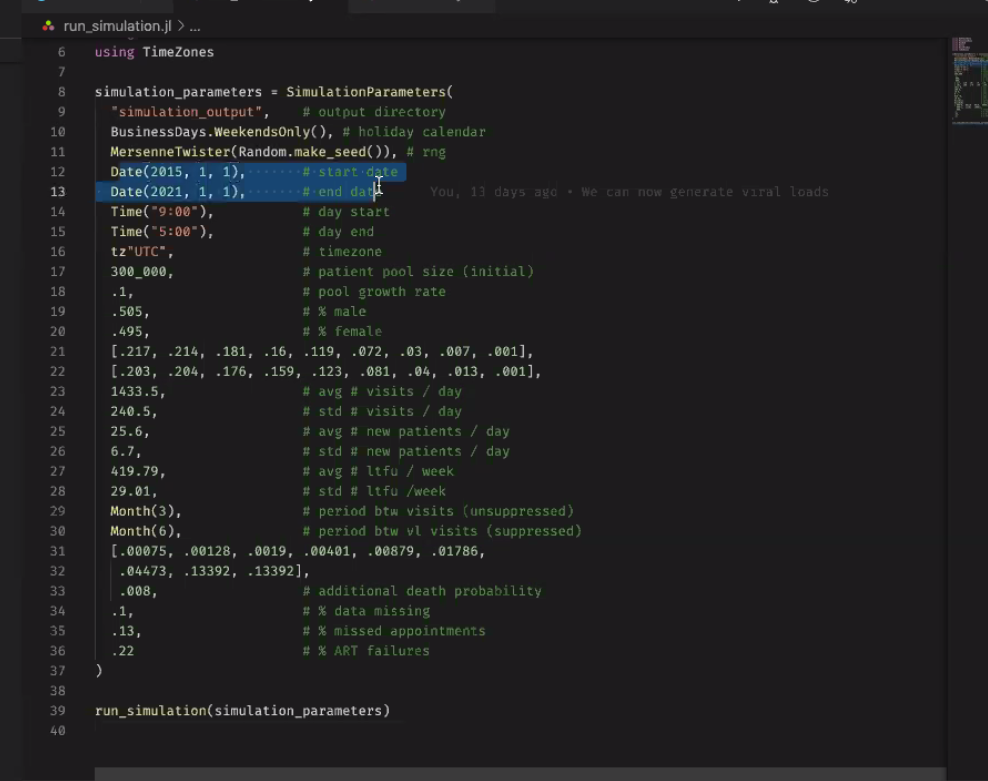
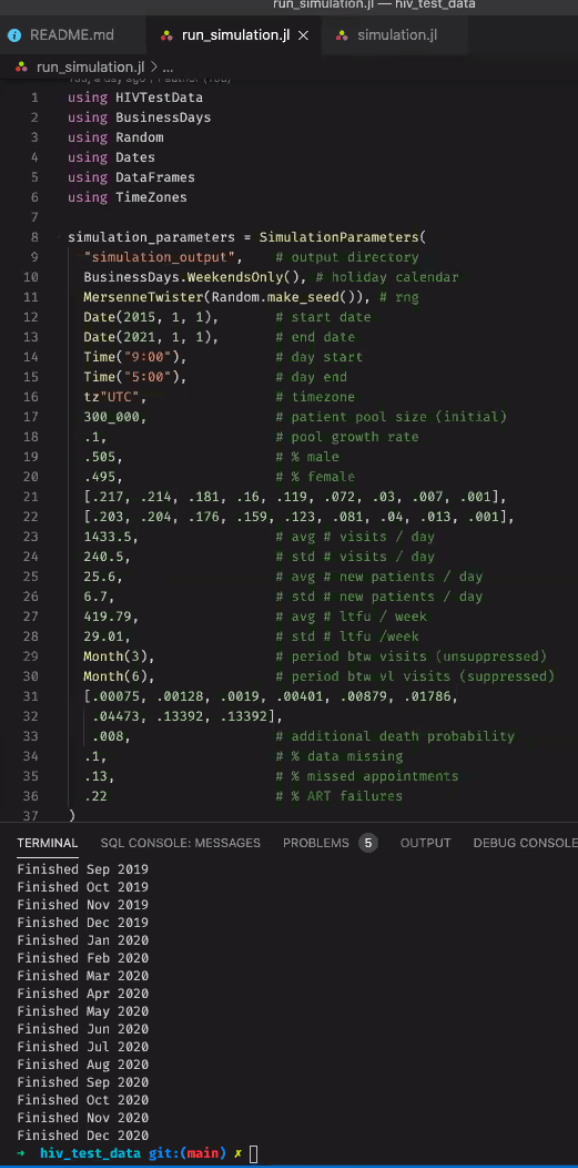
- Steps through every simulated day and outputs a file
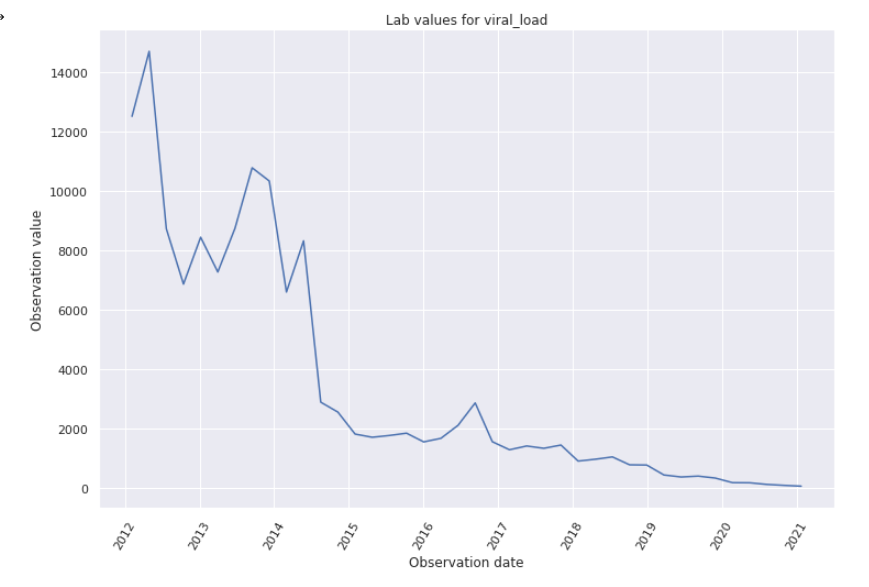
- Generating Random Lab Data: Grace/JJ demo
- Colab Notebook: https://colab.research.google.com/drive/1EMiAkbhW7TzEVlFRfUGFPIpBSgZ6GmSX#scrollTo=Uk-W16jgSf-f 5 min Demo Video: https://www.loom.com/share/ed62dc728e46401894a5cdc57ef28bd3
- Running through the Notebook generates and POSTs random, bounded, trended lab data over time. Example demo'd: Posting 40 Viral Loads
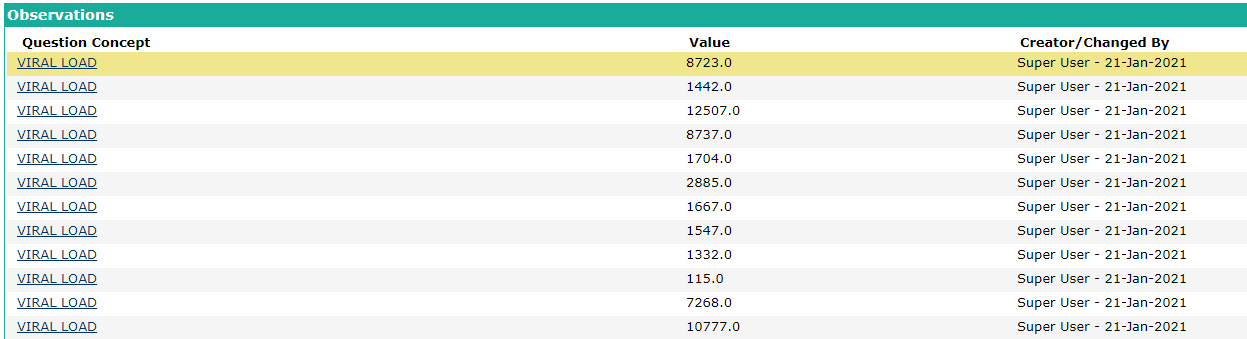
- How to Use Spark: Bashir demo
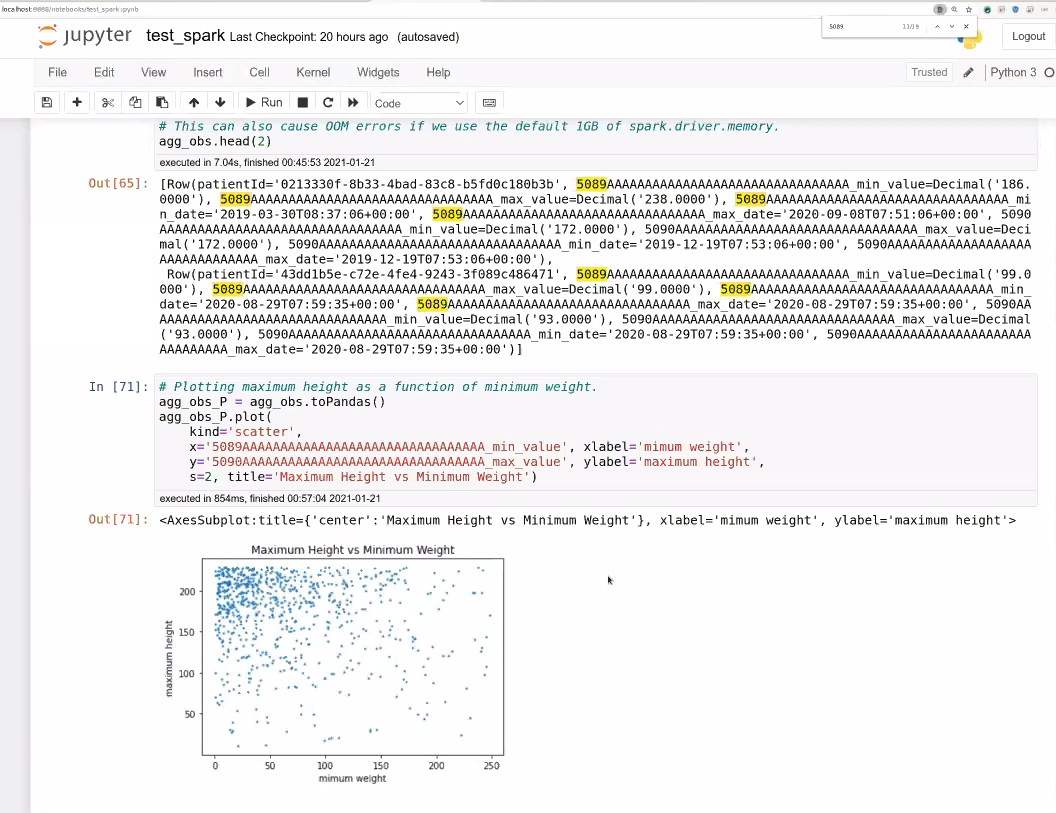
- Goal is to provide APIs over time to get base representations of the data that's being stored in FHIR for now. Bashir trying to show how this can flatten and remove the complexity of FHIR from what the person needs to understand to run the query.
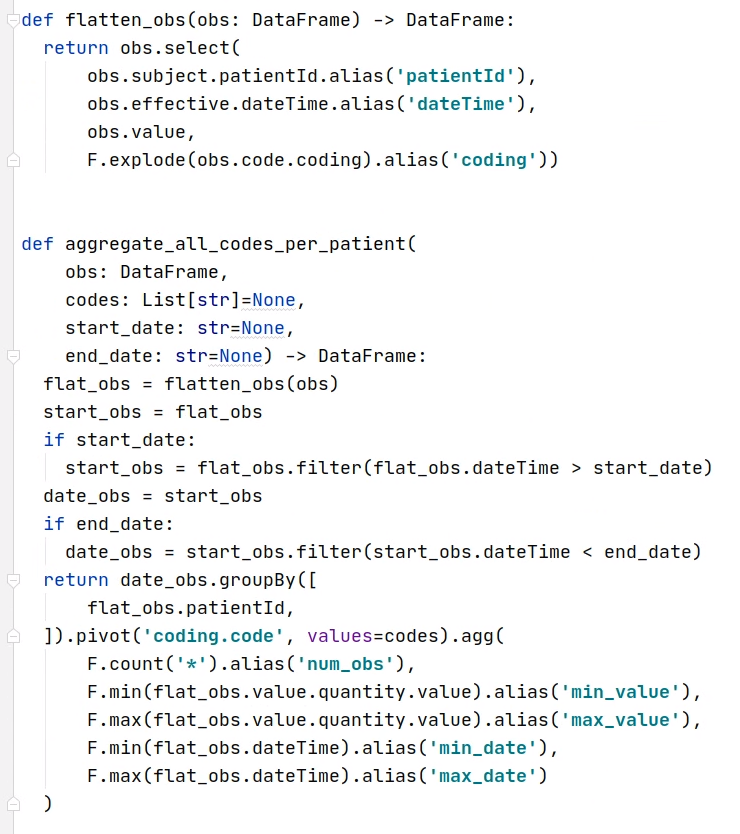
- Changing stratification and time period could take minutes to an hour. E.g. when a PEPFAR Indicator requirement
2021-01-14
Attendees: ?
Top Key Points
- Discussed the question of whether to use SQL or Python to develop indicator logic and decided to use Python.
- Discussed how Spark deployment will be done and decided to focus on the local version (with many cores) for the time being.
2021-01-07
Attendees: Reuben, Ian, Burke, Kaweesi, Cliff, Jen, Allan, Bashir, Patric Prado, Kenneth Ochieng, Grace Potma
Top 3 Key Points
- Our Highest Priority Q1 Milestone: To continuously be running beside the current indicator calculation AMPATH is using, and to show they generate the same indicators
- Other Pressing Milestone: A second implementer - esp. one with multiple sites who want to generate analytics by merging them.
Notes:
- Updates: Bashir now moved from Google Cloud team to Google Health. Opens opportunity for him to continue contributing to OMRS for a few more quarters. OMRS has been given $5k in AWS credits; however, Google Cloud could have ~$20k available if we need it. Question is not "what to do with those credits" but "what do we need".
- E2E test progress: 1 component to each that hasn't been merged. First was test for being able to spin up a container - done.
should eventually support multiple modes (e.g., Parquet vs FHIR store, batch vs streaming); we can add them gradually.the last component to e2e
- Large data set: Ian working on simulator for this (takes time to work w/ realistic data!)
- 2021 Q1 Goals
- Main Goal (Highest Priority): To continuously be running beside the current indicator calculation AMPATH is using, and to show they generate the same indicators. Next steps: Implementing those 10 reference indicators.
- Other Goal: A second implementer - esp. one with multiple sites who want to generate analytics by merging them.
- Who to reach out to: PIH, Bahmni (JSS), Jembi, ITECH (iSantePlus in every hospital in Haiti - Piotr has been involved in analytics work b/c they're looking to aggregate data into one store)
- Value Prop: If you have multiple deployments and find that managing indicators takes repeated headaches to maintain - this is for you. You can get your indicators with little maintenance, and it should work at scale. If you have many sites, many patients, many obs, this is fast, will enable interactive queries that don't impact your production system performance. The beta is early so your feedback and your org's needs will allow the squad to ensure what we're building is applicable to your use case.
- Key points from 2020 Retrospective: https://docs.google.com/presentation/d/1f0VFO0eucWZYpIDOtm8smcCNWdW_7YjdhBWS7bdfTJ8/edit#slide=id.gb1d91779dd_0_733
2020-12-18: Squad Call: Retrospective, Summary of What We Accomplished in 2021, and What We're Doing Next
Recording: https://iu.mediaspace.kaltura.com/media/1_8xg6i7yd
Summary: Thank you, everyone, for making some of this squad's objectives a success. We have made quite a significant milestone and hope to see great results come 2021. For those who could not join our last 2020 meeting, take a look at the retrospective and roadmap. Feel free to add to the list or upvote any item. Also here is the slide containing a summary of the retro and the accomplishments so far: https://docs.google.com/presentation/d/1f0VFO0eucWZYpIDOtm8smcCNWdW_7YjdhBWS7bdfTJ8/edit?usp=sharing
2020-12-10: Squad Call
Recording: https://iu.mediaspace.kaltura.com/media/1_4sqok6f1
Updates
- Allan -
- Piotr - setting up test sync via docker w/ HAPI FHIR server example to stream to. Reverting back to R4; only using R3 for buntzen part of pipeline. Currently doesn't incorporate a number of the fixes he made to the atomfeed client.
- Ian - generating some test date (goal is to finish January); Allan to follow up with statistics on variables
- Cliff - end-to-end test for changes (moving debezium settings to an adjacent file), PLIR: working on an e2e test for the changes made to enable the hapi fhir JPA support basic authentication
- Moses - connecting to OpenHIM with FHIR2 module work; presenting today
Topics
- ReadMe file too bulky
- Demos
- Moses
- Video of OpenHIM Demo:
- Analytics Pipeline High level Architecture Diagram:
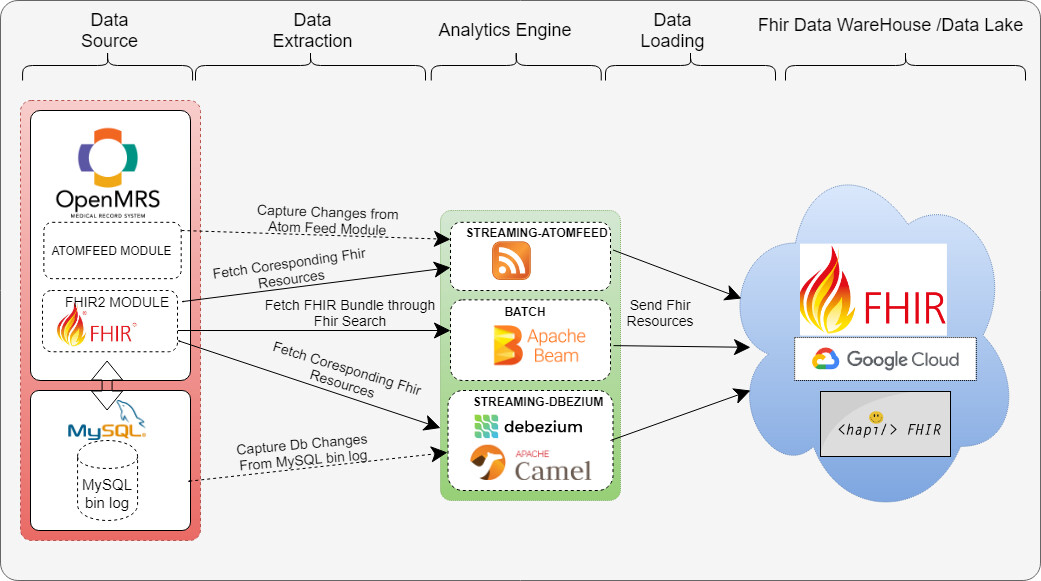 https://talk.openmrs.org/t/my-fellowship-journey-mutesasira-moses/31121/2
https://talk.openmrs.org/t/my-fellowship-journey-mutesasira-moses/31121/2
- Moses
- Need to continue Spark API discussion
2020-11-24: Standup
Recording: https://iu.mediaspace.kaltura.com/media/1_oj89pvy1
2020-11-19: Squad Call
Attendees: Bashir, Burke, Jen, Allan, Ayesh, Daniel, Ian, JJ, Jorge, Kenneth, Joseph, Sharif, Steven, Suruchi
Recording: https://iu.mediaspace.kaltura.com/media/1_ksxewulx
2020-11-17: Standup
Recording: https://iu.mediaspace.kaltura.com/media/1_yb0q1jsq
2020-11-12: Spark & Parquet prototype demo, and how to query them to generate indicator data
Attendees: Bashir, Ayesh, Brandon, Cliff, Daniel, Ian, Jacinta, Jen, JJ, Kenneth, Allan, Grace, Joseph, Mozzy, Piotr, Sharif, Steven, Vlad Shioshvili
Recording: https://iu.mediaspace.kaltura.com/media/1_dpyhepf4
- Dev Updates
- Bashir - PRs and prototype of indicator calcs plus spark implementation
- Cliff - PRs - moving debezium to DB config; adding javadocs to specs we have in AE code; getting rid of some runners for streamin. PRs wiating waiting for merge:
- Ian - trialing generating stats from Bashir's prototype - script we can plug weights into and it's a matter of getting the %'s right (in R)
- GitHub repo for weighted scripts coming
- Allan - to share more comprehensive statistics; had to make some changes recently
- Piotr - End to End testing the PR for HAPI FHIR communication with Sync: batch and atom feed streaming approach; ongoing issues w/ end to end FHIR tests; set up w/ Docker but atomfeed not installing on it due to liquibase problems. Transporting resources with a summary tag to HAPI FHIR server → HAPI FHIR server was not allowing resources with a summary tag to be saved; had to remove the tag to send.
- Jacinta
- Working on the end to end test for the pipeline
- Todo
- Switch from using OpenMrs nightly image to latest which is stable
- Piotr requesting addition of atom feed module
- Re-generade Demo Data
- Steps to generate demo data:
- The steps for generating demo data are documented here: Demo Data. It’s basically a matter of setting a single global property and restarting an OpenMRS instance. And then waiting
- Prototype Demo: Implementation of Indicator Calculation
- Why Parquet: Benefits of using Parquet
- Columnar format: Using parquet files because of columnar format - can go through those columns without actually fetching those records. Huge difference to other systems. Parquet is an open source version based on Dremnel which was originally an internal Google tool.
- Considers distributed environment: When you have huge amt of data you can't store on a single machine. You shard file into many shards, that can be distributed across many different machines.
- If you have 10's of workers - they can filter out the data they have, and just fetch the records that are of interest for our query. So you don't see benefits when running locally, but you do when it's distributed.
- Compression:
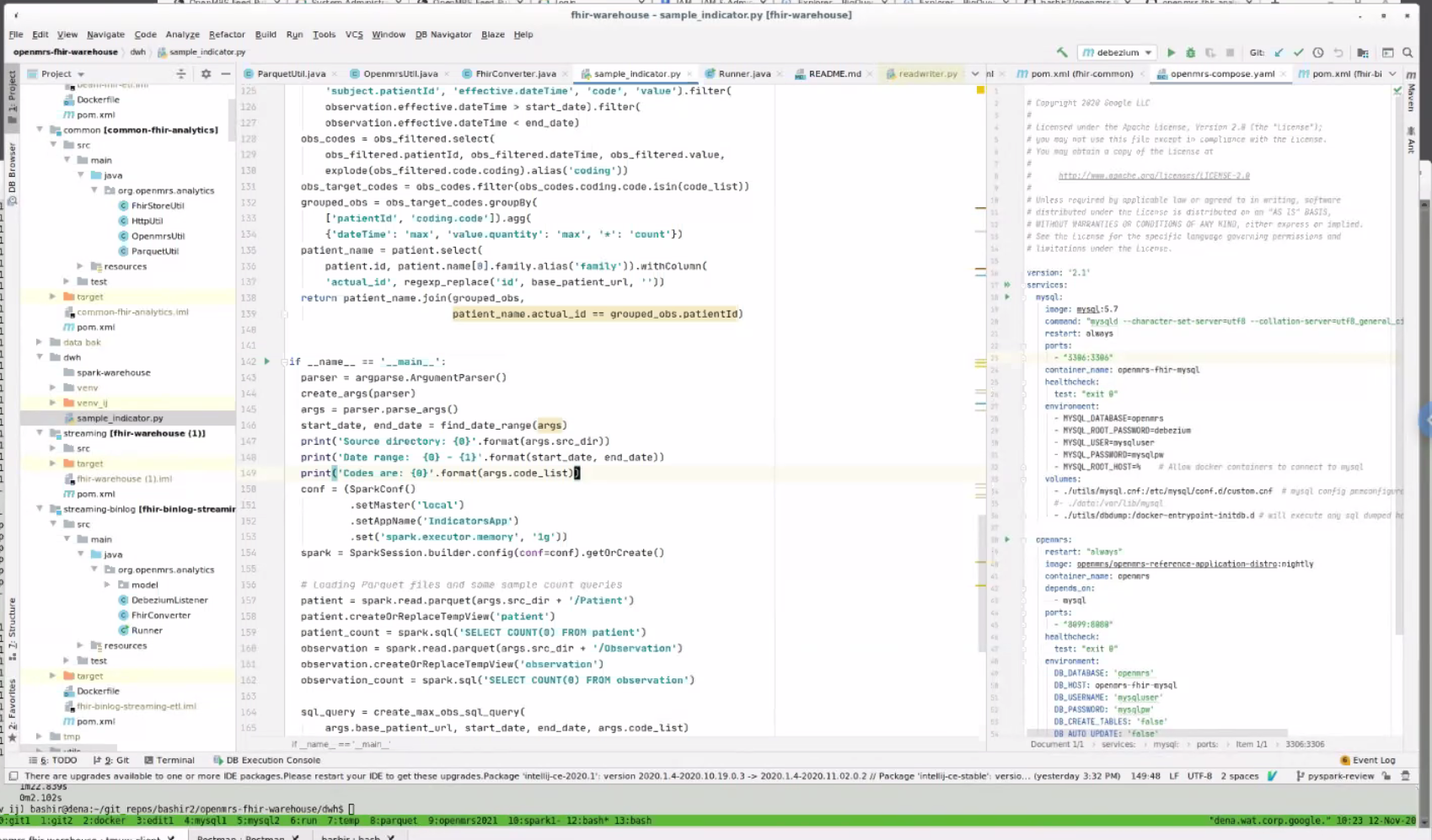
- Apache Arrow: Apache uses this internally to represent parquet files
- Why Spark
- Map-Reduce efficiency: typicaly map, shuffle, reduce- most of the intermediate steps involve writing to disk. With this approach, things go 10-100x faster than a usual map-reduce.
- PySpark = Python API to spark; so this demo is mostly Python. Can also create Jupyter notebook that talks to PySpark (Bashir just isn't doing it that way yet).
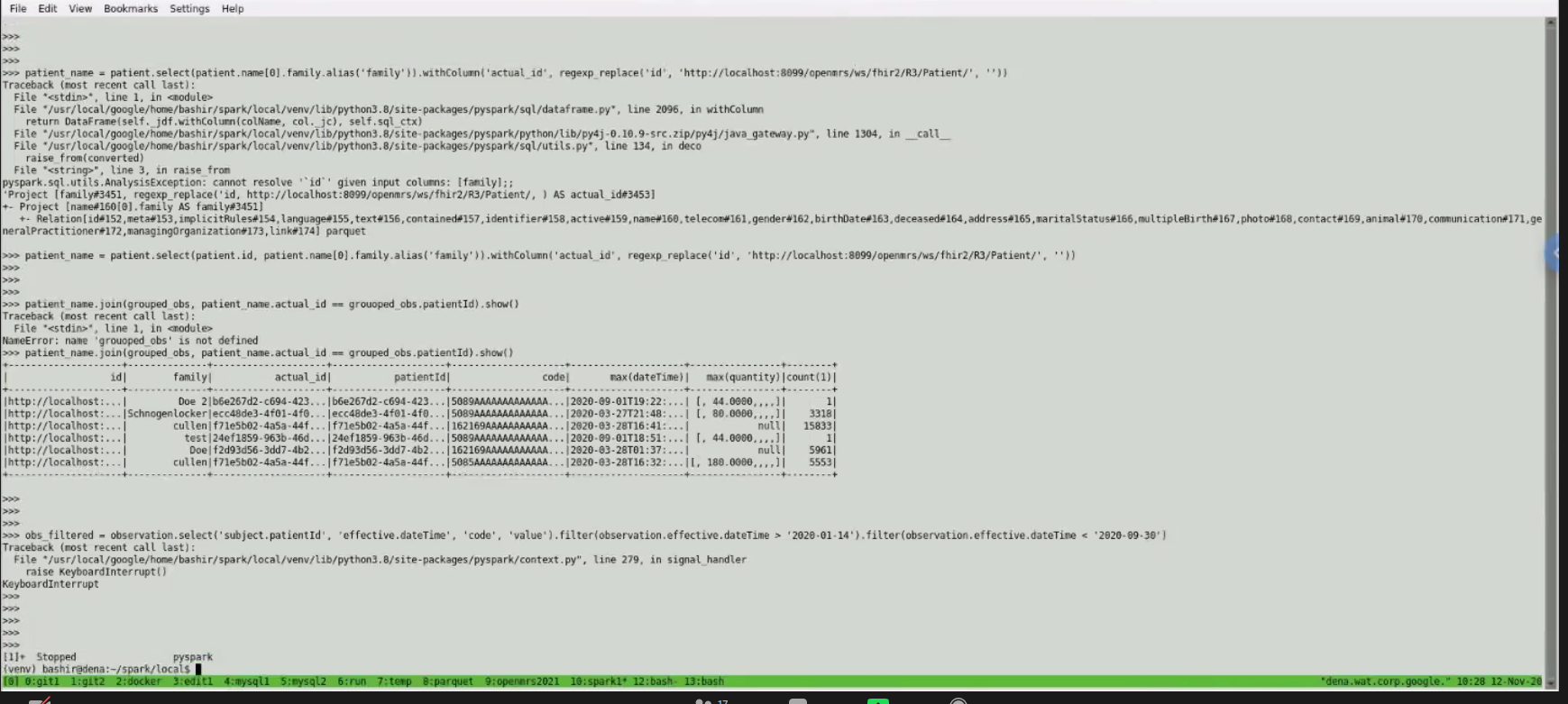
- Think Locally and still be able to scale:
 You submit your query to spark. Beauty = the same thing (the spark - submit sample indicator) can be sent to a distributed cluster - means you can think locally, but continue to run when you scale to a distributed setup. Can use this exact same command to run on local or on real Spark cluster.
You submit your query to spark. Beauty = the same thing (the spark - submit sample indicator) can be sent to a distributed cluster - means you can think locally, but continue to run when you scale to a distributed setup. Can use this exact same command to run on local or on real Spark cluster. - Example: Looking for Codes

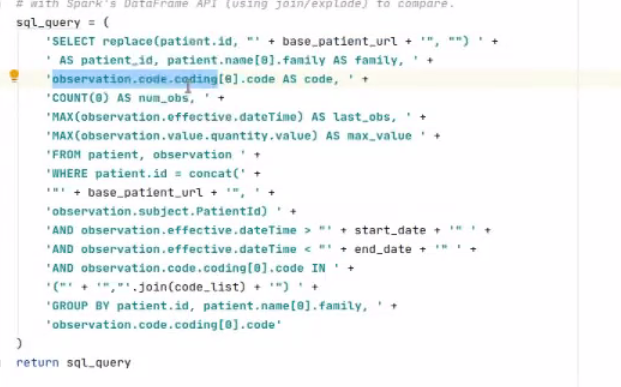
- Option #1: Write query with SQL code and FHIR:
- Can structure indicators with FHIR codes. Someone who knows FHIR and knows SQL - it should hopefully be easy for them to write these queries

- Option #2: via Python querying Spark API
- Using Python to query Spark dataframe which is seamlessly distributed on multiple machines
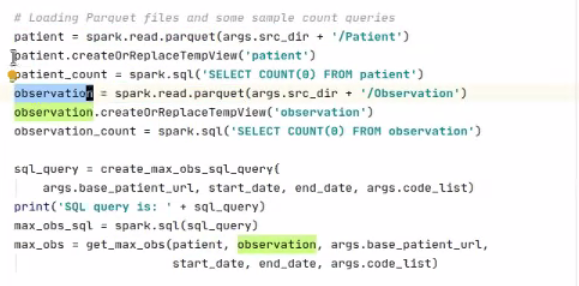
- Can just focus on columns of interest:
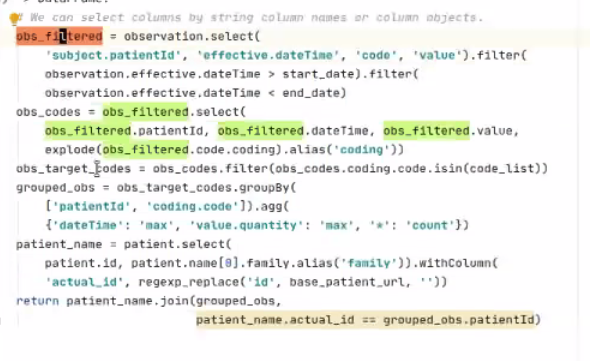
- Pros/Cons of the 2 Approaches
- Performance: SQL query may have done better; unclear b/c small test set size
- Learning Curve: Spark API took 2 days to learn how to query their API.
- Readability: with SQL, clearer to see if you're calculating things correctly. SQL is more likely to be readable/familiar.
- Maintenance: Spark API query more maintainable than SQL query as your queries grow. E.g. creating an API into our own server to query indicators could save time longer term.
- TODOs
- More feedback next week
- Slack discussion on Option 1 vs 2, and Python vs Java
- Create Google Cloud infrastructure a some kind of notebook to query it
- Why Parquet: Benefits of using Parquet
2020-11-10: Standup
Recording: https://iu.mediaspace.kaltura.com/media/1_km9wjf5z
2020-11-05: Squad call
https://iu.mediaspace.kaltura.com/media/1_xwiwud01
2020-11-03: Standup
Recording: https://iu.mediaspace.kaltura.com/media/1_52jeny9e
2020-10-27: Standup
https://iu.mediaspace.kaltura.com/media/1_jm4887sf
2020-10-22:
Recording: https://iu.mediaspace.kaltura.com/media/1_0f2p04pj
Attendees: Allan, Bashir, Burke, Grace, JJ, Suruchi, Daniel, Ian, Jacinta, Jorge Quiepo
Welcome to Suruchi, sr dev from NepalEHR with interest in implementing analytics engine at their implementation, and new OpenMRS PM/Dev Fellow.
Reminder: Squad Showcase next week
Dev updates:
- Bashir has been working on simplficiation of camel
- Allan
- Converting atom feed config service logic
- Performance assessment of batch (patient, obs, encounters)
- Needs to add additional FHIR resources
- Bashir command line flag - can specify resources + search (this is because batch mode built on top of search api)
- OpenMRS Docker file has problems - liquidbase migration is happening despite update_db setting at false
- Jacinta
- New to squad from AMPATH
- She will be taking over issue of docker file https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics/issues/38
- Also will take on issue of creating an integration test : https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics/issues/8
- Moses
- New to squad, looking for opportunities to work on PLIR
- Working on config issues related to R4 and R3 via atom
- Use HAPI FHIR client to load resources into generic Bashir - https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics/issues/29
2020-10-15:
Attendees: Bashir, Grace, Cliff, Daniel, Ian, Jacinta, Juliet, Allan, Mozzy, Piotr, Sharif, Vlad, Jen, JJ
Recording: https://iu.mediaspace.kaltura.com/media/1_h7p70dss
Dev. updates:
- Piotr - finishing up my couple of PR by next week, on the streaming docker setup and HAPI fhir client use
Addition of 2 new devs to team
- Moses Mutesa - fellowship mentor
- Cliff - volunteer
MVP Progress
- Want to have a way to transform data from an OpenMRS intance, in batch and streaming modes, trans data into FHIR that's easily converted into Spark, so that we can run queries at scale.
- Success metric: When we can run FHIR queries on spark at scale.
- Batch issues have been resolved and can create in Parquet.
- In a few weeks, how much to focus on original 10 PEPFAR metrics, given current CQL discussions? Can expose Metrics API that can be consumed. More updates to come from Vlad in next 2-4 weeks. If we integrate some of their work, means we'd be able to map to ~15 indicators.
What's the next step for getting from FHIR to indicators?
- (1) Next 2-4 weeks, focus remains on getting FHIR queries to run in Spark at scale. Getting engine running (as opposed to just a few metrics) - once that's running, (2) try implementing the example list of metrics, (3) look at whether there's an automated way of handling metrics like those examples in the future.
- Squad needs to focus on (1), the mission-critical groundwork.
- Summary: Datasource: OpenMRS. Tool to get it over: Parquet. Structure: FHIR. ETL Query tool: Spark. Means analyst can set up workspace to run ad hoc queries quickly at scale that run in seconds without impacting production. (E.g. every patient that visited my clinic within the last few months with HIV) Future: To be able to use other analysis/warehousing tools, more work to do.
Ampath example: SQL scripts generate report values. E.g. How many patients are on ARV: Take QID 123 and QID 345.
So - is it fair to assume that almost everything else but the concepts is the same? This is why Vlad's mapping tool is of great interest. Users need to be able to back up through the logic to show the result can be trusted.
How do we represent those SQL case statements? Can add logic into your FHIR module. E.g. my unified viral load concept
Ian investigated how TX_PVLS was calculated in 3 different implementations. All 3 were using slightly different definitions, even when using the exact same concepts. Some stored as obs, some stored as orders.
How PLIR/Notice D work is Different
- Indicators calculated in OpenHIM; focus is on passing FHIR resources through
- Prove extraction of the relevant dataset in the right format
Who's doing what next?
- Demo for implementers at next Squad Showcase
- Examples of a few calculations - Ian?
- JJ to share SQL case statements with Vlad & Squad
2020-10-08: Presentation of Analytics Engine approach and work so far & FHIR background
Recording: https://iu.mediaspace.kaltura.com/media/1_4ievjc2p
Attendees: Allan, Bashir, Burke, Ashtosh Padhy, Cliff, Daniel, Kenneth, Michael Gehron, Vlad Shioshivili, Ivan N, Piotr, Suruchi, Tendo, Ian, Juliet, Moses, Sharif
Overview presentation of the Analytics Engine Squad's work so far, & discussion with Michael & Vlad from PEPFAR PLM team.
- Emphasis from squad on performant solution that can handle large quantities of data - this drives our architecture decisions. Planning to access info through a Metrics API.
- FHIR was chosen as the API for talking to OMRS. FHIR is also the main data model for the Analytics Engine to benefit more from standard tools built on top of FHIR.
- FHIR2 module/bundle can generate FHIR resources, so Analytics Engine can rely on that; default information model is FHIR.
- The fhir2 module is currently a series of translators that transform into FHIR. Long term hope is to replace stuff we're storing in custom OMRS formats with FHIR, so we speak FHIR natively. Goal of module for now is to transform 80% of that custom OMRS data into FHIR.
- The FHIR2 module update recently released: Reading the vast majority of data in OMRS - can read patients, orders, conditions; some writable parts of API still WIP.
PEPFAR logic changes happen so frequently, so the PLM work is aiming to include a logic model that they (PEPFAR?) would keep up to date so implementers could just reference that, and not have to each go through the massive work of logic updates.
2020-09-24
Present: Vlad Shioshvili, ALlan, Bashir, Christina, Daniel, Burke, Ian, Ken O, Michael Gehron, Tracy, Grace, JJ, Jen
Recording: (PEPFAR PLM demo starts 14 minutes in) https://iu.mediaspace.kaltura.com/media/Analytics+Engine+Squad/1_4759yb4v
Agenda:
- Discussion on CQL and PEPFAR metrics.
- Update: Progress with FHIR schema and Spark - not done; next time
- Update on overall Squad progress: the analytics squad has created prototypes for extracting data using FHIR in both batch and streaming modes. However, we have not done any work on indicator transformations/aggregation
- Decision: Decide btwn Debezium embedded and Camel Debezium - plan was to use Debezium directly, but Allan has done some tests and Camel seems like a better idea - so this PR is going forward.
- PR for adding basic auth (username/pwd) from Piotr.
@Vladimer Shioshvili continued the presentation on PEPFAR's Patient-Level Monitoring for M&E Proof of Concept as well as gave a live demo. Slides: https://docs.google.com/presentation/d/1t9astN7NboSycFax0vNgZxVJ2Tc6OJF3_3HJaJGGAIM/edit
- Questionnaire resource mapped to FHIR - collects questionnaire responses which are also mapped to FHIR.
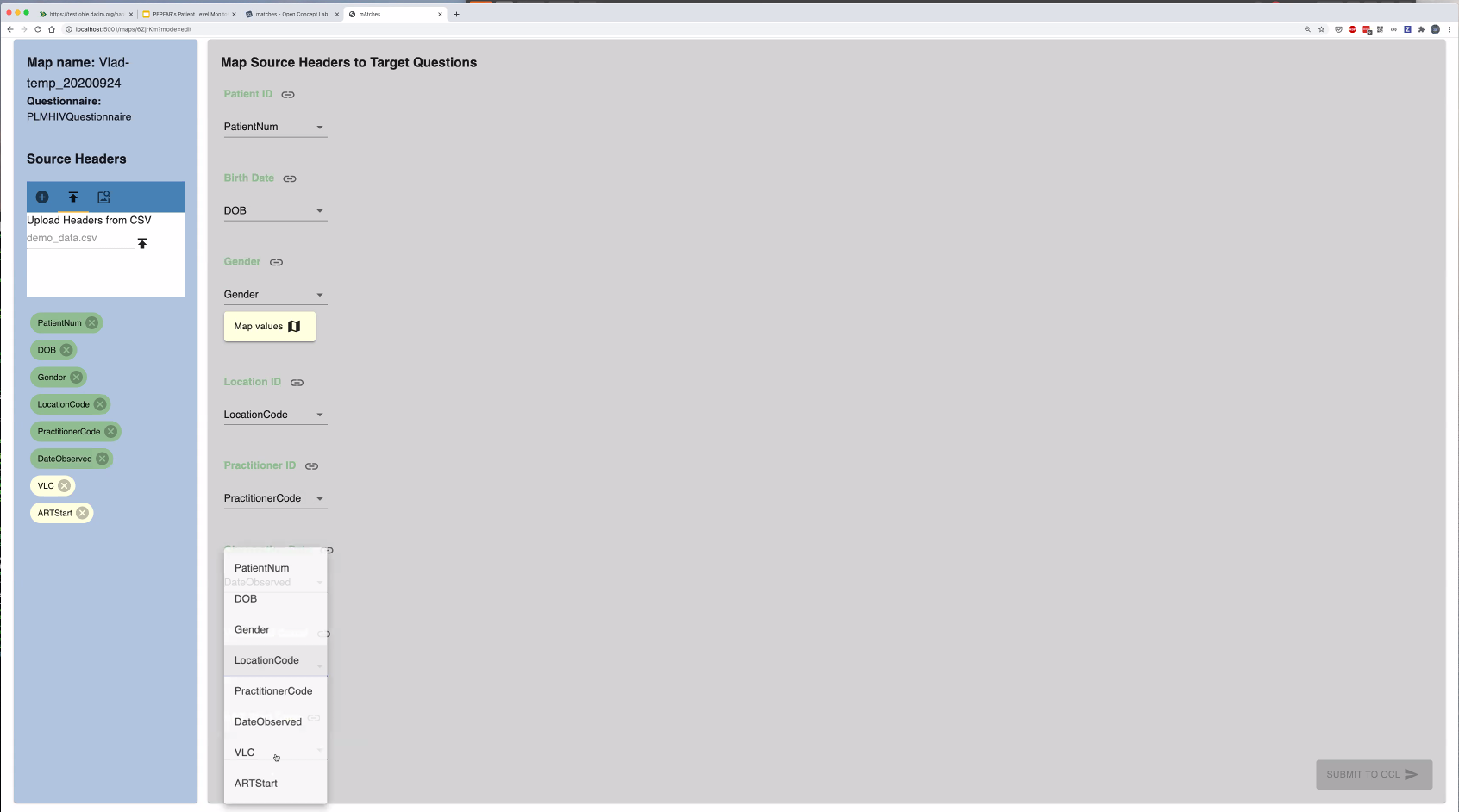
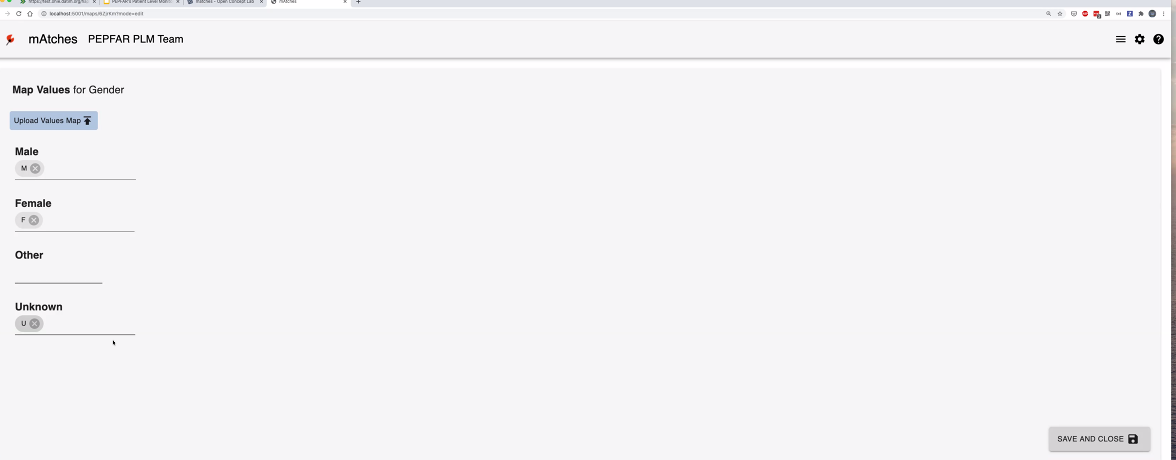
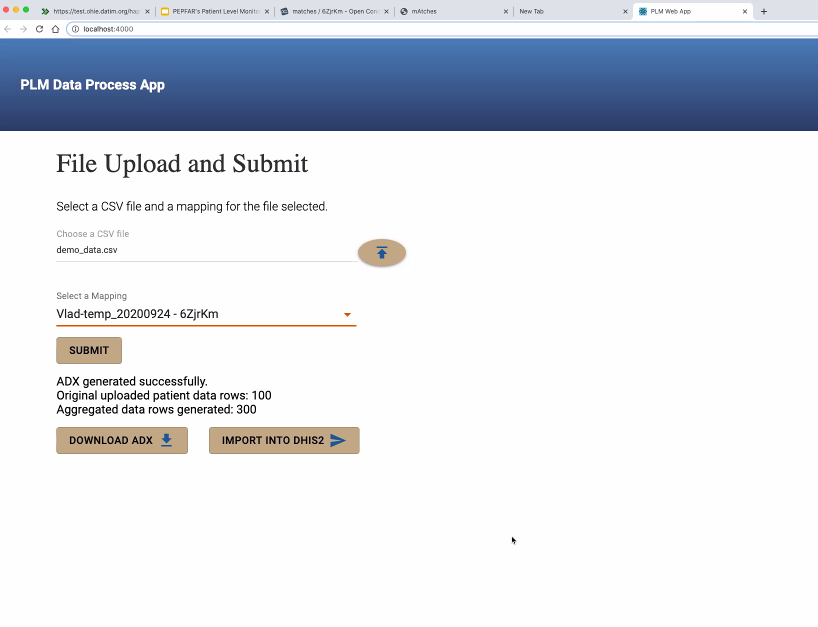
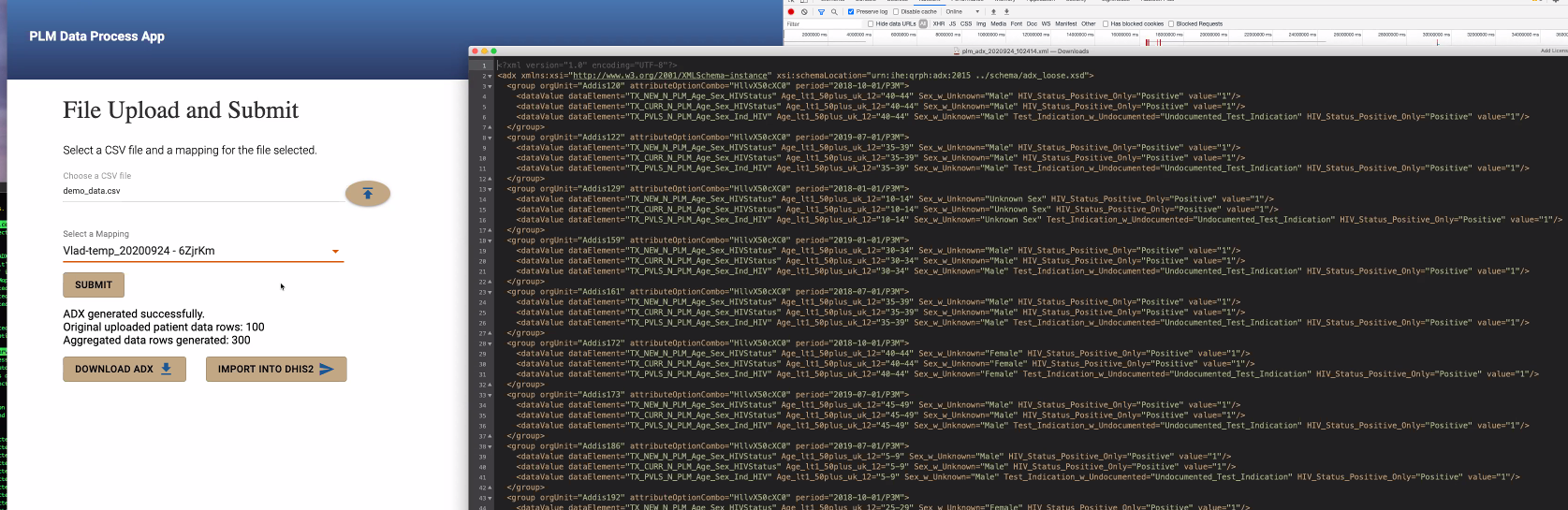

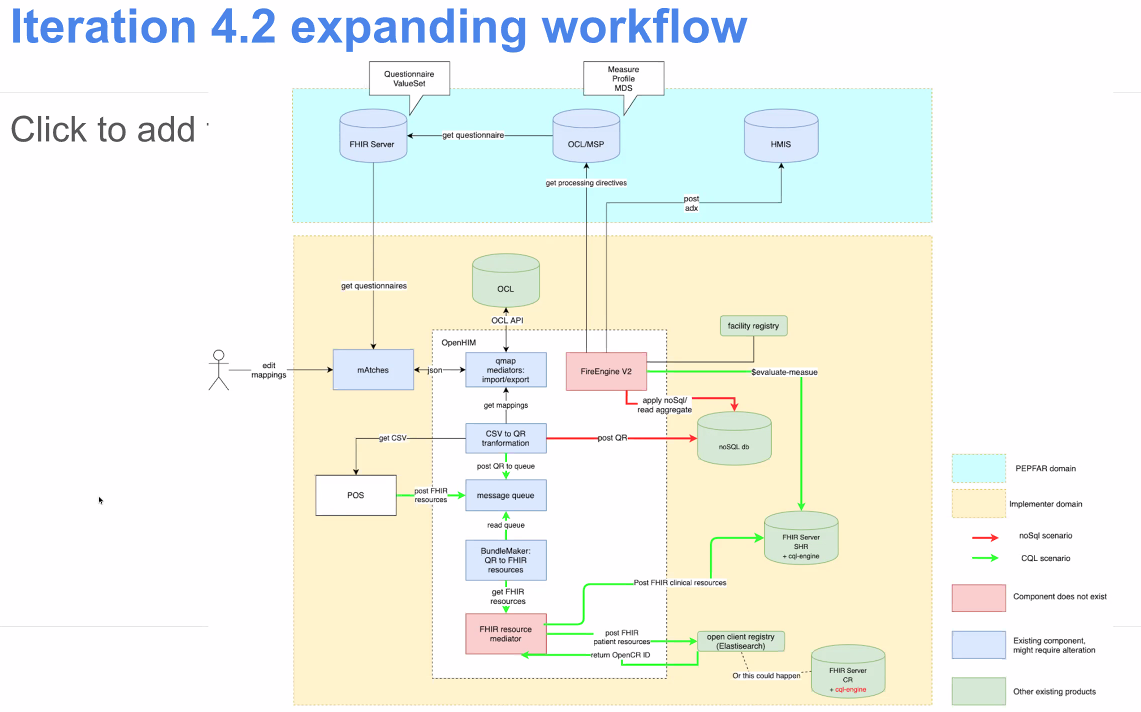
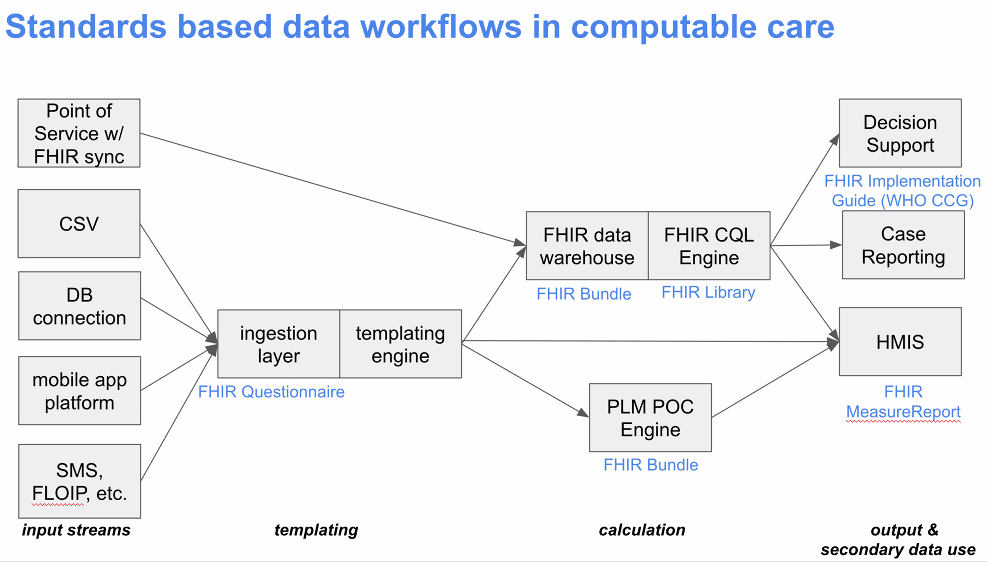
Working with IntraHealth on integrating the openclient registry to reconcile the patients across different point of service applications. So when they receive messages from multiple systems, want to make sure one person is indeed counted as one person. A lot of times, false positive LTFUs happen because of a transfer of a patient to another system, that didn't get captured as one patient moving.
Looking to use CQL instead of custom agreggations they have written right now.
Should be able to share Repos within a couple of weeks.
Next Steps:
- ...
2020-09-17
Agenda:
- Demo from group from OpenHIE's Data Use Community (DUC) who want to generate MER indicators on FHIR
- Update: Progress with FHIR schema and Spark [next time]
- Decision: Decide btwn Debezium embedded and Camel Debezium [next time]
2020-09-10
Present: Allan, Bashir, Burke, Daniel, Debbie Munson, Ian, Jen, JJ, Juliet, Mozzy, Sharif, Tracy, Grace
Recording: https://iu.mediaspace.kaltura.com/media/1_gkdr9uvr
- Announcements
- Product Management update - JJ Dick will begin co-leading Product Management of the squad with Grace
- Call timing update - please do this poll: https://doodle.com/poll/hy8ekhwxy9n3m7ck so we can make this call accessible for more people
- Other announcements or work people would like to update the squad about?
- Allan: to demo his progress

- Takes < 3 mins to extract 3,000 datapoints from ~500 encounters; tested with encounter and obs
- Asks a lot of the FHIR2 module for performance (current focus of FHIR squad has been resource mapping, not performance, yet); could be further optimized
- Allan suggestion: People should be able to extract the data however they want, but FHIR as the preferred/recommended mode
- Next steps: How can we move forward and get work done together?
- Schema Talk Thread: https://talk.openmrs.org/t/to-schema-or-not-to-schema-deciding-on-a-foundation-for-our-analytics-engine/29953/11
- Problem: Need to have flexible engine, for where FHIR won't help us (e.g. where a new table cannot be mapped to FHIR, or you have a separate labs DB which you want in your analytics warehouse where you can query it). For Ampathy, FHIR will work ~80% of the time, but may not work all the time. So: Do we want to go for schema or schema-less warehouse?
- Allan's recommendation: Support both - FHIR as main schema, and have flexibiltiy to store data, have your analytics engine access that
- Bashir: For first prototype, use SQL on FHIR. You can still bring any type of data into the warehouse that's not FHIR. Current prototype uses FHIR API to pull the data. Eventually we could bring an extension into the pipelines that creates a view, brings the data forward anyway. Once you have custom data in your warehouse that you want to use for analytics, then by definition, you have to use custom logic anyway.
- Burke; FHIR not ubiquitous enough, don't want to lock ourselves in.
- Mapping to FHIR is not a requirement.
- Decisions
- Agreement: We're moving forward with at least FHIR.
- What's next? Try moving forward with Spark.
- Debezium? Discuss next time.
- New meeting time: Thursdays at 2pm UTC
- TODO: JJ to intro squad to other group from OpenHIE's Data Use Community (DUC) who want to generate MER indicators on FHIR; try to get them to demo next time
2020-09-04
Recording: https://iu.mediaspace.kaltura.com/media/Analytics+Engine+Squad/1_iw9pijl5
- Kenneth Ochieng (Intellisoft) shared work for DS Notice D as proof of concept system for integrated approach to patient-level reporting
- Using Bahmni for point of care system
- Using Bahmni's Atom Feed Module to expose data
- Sending patient data using FHIR format to OpenHIM
- Storing FHIR data into HAPI FHIR server within HIE as shared health record (SHR)
- Using FHIR Measure resources within HAPI FHIR server
- Will use CQL engine against HAPI FHIR server to calculate measures and share them with DHIS2
- Defining development process
- Making decisions: use Decision Making Playbook
- Slack channel: #analytics-engine
- Handling tickets
- Consider using github during prototype stage
- May re-visit and consider JIRA once a shared approach & repo(s) has been decided
- Repository
- Handling Pull Requests
- Would like to have a server within OpenMRS for testing (e.g., ae.openmrs.org for "analytics engine")
- Large demo dataset is ~200 GB
- At least 8 GB (16 GB would be preferable)
- Could repurpose sync servers
- Making decisions: use Decision Making Playbook
- Make the call about data store and general structure/approach.
2020-08-28
Recording: https://iu.mediaspace.kaltura.com/media/1_zo38ckft
- Discussion on the road-map; request for feedback
- Schema selection choices and flexibility
- Schema evaluation (e.g. OMOP, SQL; is no-SQL approach possible?)
- Discussion on talk: To schema or not to schema… deciding on a foundation for our analytics engine
- allan kimaina considering use of Apache Parquet as initial format for data
- How to process data?
- We have a bias toward Apache Spark
- Tools for handling data workflow
- Delta.io is a tool allan kimaina has been evaluating
- Apache Beam was suggested by Bashir Sadjad
- Bunsen is an interesting tool backed by Cerner that allows
- Would like to aim for initial examples
- Using FHIR Data for a PEPFAR report using FHIR
- Use a custom datatype in early examples to demonstrate that the pipeline is not FHIR-only
- CQL support
- CDC seems to have a preference for PowerBI - we can expect this to be a priority use case (exposing or transforming data into a format that PowerBI can use)
- Stretch goal: Running PythonNotebook on top of data
Action: Make the call before or by next call about data store and general structure/approach. allan kimaina & Burke Mamlin owning follow-up.
2020-08-21
Recording: https://iu.mediaspace.kaltura.com/media/1_rxkt7fss
Attendees: allan kimaina , Bashir Sadjad , Burke Mamlin , Ian Bacher , Jennifer Antilla , Juliet Wamalwa , Kenneth Ochieng, Piotr Mankowski , Tracy, Grace Potma
- Dev. updates
- Batch implementation pushed to same GH repo. Demo'd recently to FHIR squad. https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics
- Piotr working on dockerized version of streaming app to synchronized between an OMRS and HAPI FHIR instance
- POC needed in 6 weeks - so Piotr working on getting atomfeed solution cleaner/simpler
- Review of MVP goals
- OMOP/schema feedback
- Presentation from Alan:
- Proposal: Use FHIR as intermediate
- Discussion: How to approach building FHIR schema to prepare for other use cases that would otherwise be forced to create their own pipeline/engine if they don't use FHIR
- Need to support other formats as well
- Discussion on Talk: To schema or not to schema… deciding on a foundation for our analytics engine
- Presentation from Alan:
- Proposals for issue tracking, code location, and code review (TL;DR; GitHub)
- Agreed on using GitHub for issue tracking in this squad
- Bashir on Vacation next 2 weeks
2020-08-14
Attendees: Antony, Burke, Allan, Bashir, Christina, Daniel, Debbie Munson, Jayasanka, Jen, Juliet, Tracy
Recording: https://iu.mediaspace.kaltura.com/media/Analytics+Engine+Squad/1_7yw4tayq
- Welcome!
- Antony (Palladium), Debbie (PIH)
- Announcements
- Awesome job on Squad Showcase!
- Did you notice we're now Analytics Engine Squad? For example, our zoom call shortlink is https://om.rs/zoomaes
- Renamed #etl Slack channel to #analytics-engine to reflect this
- Dev. updates
- Bashir: Code for monitoring changes, transforming data later into a FHIR resource. Opensourced now
 https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics
https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics- Location: Google Cloud Platform for now while still getting started. Apache License. Can go to OMRS if that's a better place in future.
- Please check it out!
- Allan: Evaluating w/ Cornelius (Ampath FHIR expert) - went through data tables. Found 70% of Ampath data represented w/ FHIR; what about other 30%? Looking to expand that.
- To use FHIR as intermediate storage, we definitely need a custom schema that covers that other 30%.
- Challenge: How to limit this so people don't depend too much on custom schema. This wouldn't realize the benefit of the entire pipeline.
- Some implementers not comfortable with FHIR - this would enable them to use custom schema. But, adds scope: Requires us to support two schemas.
- Bashir: Code for monitoring changes, transforming data later into a FHIR resource. Opensourced now
- Continue discussion on data warehouse schema:
- Still need to discuss schema. E.g. OMOP.
- API to access schema? At Google, history seemed to be SQL was trusted, i.e., SQL as an API for accessing data. The context is BigTable to SQL based APIs migration.
- At the end of the day, the query complexities are still there, even if we pick a non-SQL API.
- For end-users: Agreed that consumers need to have tooling at the end that allows them to get the data out - even without knowledge of SQL.
- For under the hood - Schema Flexibility: Concern around committing to relational database approach if we don't have to
- Nice because people can bring whatever they want
- Hard because it will be harder to build things on top
- E.g. Palladium: does development, other players consume data. Need frameworks that empower those users to come up with their own reports. So many funding agencies that all have their own reports (e.g. CDC, USAID, DOD), have different report requests at least every week! Need to be readily consumable for ad-hoc reporting. Where everyone understands queries for what's in the system.
- Being able to perform ad-hoc reports could be an argument for SQL
- Not clear that OMOP has wider adoption than FHIR. Well adopted in clinical research community.
- Keep researching/asking? Or just start with FHIR?
- Using FHIR for data analytics tools is already happening. Unclear: Are people widely comfortable with OMOP? Easier to work with. Primarily designed for de-identified data.
- We always have the option for FHIR→OMOP in future as there are open source tools for that transformation.
- OMRS quite involved helping set up OHDSI community
- FHIR background is to support both data structure for SHR and for analytics
- Where do we go from here?
- TODO: Allan to review OMOP
- TODO: Grace to set up meeting w/ Squad & James/Carl re. ADX/OMOP advice
- TODO: Burke to start Talk conversation around initial schema (w/ link to Analytics on FHIR)
- Still need to discuss schema. E.g. OMOP.
- Concrete MVP goals:
- Single machine pipeline, while easily scalable (note on MySQL bottleneck)
- Horizontally scalable warehouse
- Metrics API with a minimum set of indicators
- Implement the 10 common indicators; show people how quickly they can be calculated. Idea is this could be a separate module that uses the warehouse.
- Deploy as docker image; they get an end point they can query to issue queries to underlying data. But has to be scaleable. OMRS itself not horizontally scalable. MySQL would be the bottleneck for scalability in the data pipelines.
2020-08-07
- Recording: https://iu.mediaspace.kaltura.com/media/1_pzweel3o
- Attendees
- Updates
- TODO - Grace set up call w/ James K & squad tech leads
- TODO - Grace consolidate visuals of ETL demos from implementers
- Deidentification of randomized data set ongoing by Allan at AMPATH
- Bashir experimenting with converting data to FHIR resources and pushing to a FHIR warehouse; includes bulk-update. To make open source code available to all next week.
- This code can be used to extract OMRS data as FHIR resources. Generic tool, not just for analytics, even though original use case was to push to FHIR warehouses.
- Review of hot-spots for run times
- Proof of Concept
- Looking for 1+ more site
- Need to i.d. what the intermediate schema is that they're okay with (e.g. some for/against FHIR) - is there any other analytics schema out there that makes it easy to come up with the concepts around it?
- OK to use SQL as main interface? (commitment that end product would be used)
- Need to i.d. intermediate schema, assuming it's not FHIR.
- Just build and get feedback from prototype?
- Do we need separate mechanisms for standardized indicators?
- Need to get to a data warehouse where we can get to those specific features; maybe phase 2 we get to specific querying
- TODO: Tracy to post and s
- Other standardized schema examples: OMOP, I2D2
- OMOP use case suggestion: Different way to transform the data into a standardized format, to have common data for analytics. Another way of trying to do data analytics / warehousing at scale. Advantages is that because it's been standardized as a model, a lot of tools being built against it.
- Existing libraries for converting FHIR→OMOP
- OHDSI: https://ohdsi.github.io/TheBookOfOhdsi/ OHDSI Common Data Model: https://github.com/OHDSI/CommonDataModel/wiki OHDSI Analytics Tools: https://ohdsi.github.io/TheBookOfOhdsi/OhdsiAnalyticsTools.html
- OMOP use case suggestion: Different way to transform the data into a standardized format, to have common data for analytics. Another way of trying to do data analytics / warehousing at scale. Advantages is that because it's been standardized as a model, a lot of tools being built against it.
- Building on REST API FHIR store loses some of the advantages of storing in SQL
- Need to support not-cloud-based: We can provide tools (e.g. Spark), but responsibility of implementers to manage their own cluster if they want scalability beyond single node.
- Would be nice to provide these sites w/ different versions of Docker component files for such cases.
- "Engine"
- Deidentification
- Looking for 1+ more site
2020-07-31: First Squad Call
- Recording: https://iu.mediaspace.kaltura.com/media/Analytics+Squad/1_id8660id
- Attendees
- Burke Mamlin , allan kimaina , Bashir Sadjad , Christina White , Daniel Kayiwa , Dimitri R , Ian Bacher , @Jayasanka, Jen, JJ, Mike, Steven, Tracy
- Introductions
- Technical Leads Allan & Bashir
- Mekom: Keen to include analytic platform in work for clients
- Jayasanka: Working on DHIS2 reporting module, love for analytics/viz
- AMPATH: Have been supporting hacky ETL solution; excited to have more robust solution
- PIH: Often less than ideal approaches to ETL & analytics, excited for something that helps guide things forward
- KenyaEMR: Steve - historically has seen reporting solutions have all been suboptimal – e.g. having a ministry report running all night
- ITECH: Christina: Hoping to implement in Haiti. Tracy: secondary use of data at large scale; researcher of predictive analytics & clinical decision support
- Our prototype goals
- Clarify purpose as prototyping (it’s unknown what final tool/product will look like)
- Specific indicators
- Scalability (run on 1+ nodes)
- Goal is to create something useable soon (i.e., get to a working prototype people can actually use)
- Lessons learned from OMRS19:
- Common need for flattening encounters (e.g. people trying to analyze How many patients did we see where X happened?)
- Creating a table for every form - an idea from prototype approach that suggests how it will work to automatically produce e.g. a CSV for each form
- Lessons learned from BIRT & others:
- Our data model is constantly changing; the questions you want to answer are always new (nature of medical info - which test is done changes year to year)
- Need tooling that's at production level to not have to define our whole schema up front. Use standards & tooling conventions wherever possible.
- Need to echo standards so we don't have to build multiple aspects - tools coming to existence built on standards (e.g. expect to see more of this w/ FHIR). Want tooling we can support in 1-2 years.
- FHIR as (1) first intermediary step/data store w/ initial transforms, +/- (2) build your own extension as needed w/ transforms you need
- There will no doubt be efforts outside of OpenMRS to transform FHIR to OHDSI's common data model
- ITECH: working on prototyping way to pipeline data into a side-by-side HAPI FHIR store for q. OMRS instance - hope is to use some kind of ETL
- Bashir has been experimenting with extracting into FHIR schema
- Will need to discuss schema more!
- Leveraging recent community EIP work
- Debezium chosen as way to broadcast elements, create an outbound from OMRS to get data from
- Now need tool to help route messages (and well dev'd/designed, saves ++ dev time) - Apache Camel well-suited, but can't drop Camel on EIP side
- OMRS should be able to spit out FHIR messages out of the box. Until it can, need to identify the layer that does this and who's getting it done. Ideally FHIR subscription model is what OMRS should be able to do. So "if you need X data, subscribe to OMRS and FHIR model can generate for you". Mekom willing to support full-time developing ability for OMRS to support doing this.
- ETL tech layer should expect to receive FHIR data - not the job of the ETL pipeline. Extract FHIR and transform as needed from there.
- Need reliable event generating system. That's what the pipeline pulls from. (Right now in OMRS this is basically MySQL)
- Clarify purpose as prototyping (it’s unknown what final tool/product will look like)
- How often we meet
- Weekly
- First priorities:
- Requirements & what's getting built - ground in prototypes groups have already made
- One prototype every squad call? (20% of time on prototypes every week)
- Send doodle (or Slack poll) for ?Wednesday, next presenters
- Sprint structure
- Where we collaborate digitally
- We use Talk for discussions and decision-making (documenting decisions)
- We use Slack #etl to chat (and assume those discussions will never be seen again)
- Data environment
- Centralized server with unified sample dataset that we can use to do development and analysis
- Cloud vs On Premise
- Any other role clarification
2020-07-30: Focused discussion on PIH's ETL work
Attendees: allan kimaina Bashir Sadjad Ian Bacher Grace Potma Mike Seaton Mark Goodrich
- PIH's ETL infrastructure:
- https://github.com/PIH/petl
- Chose Pentaho because concern about need for other devs who understand more cutting edge tech if they chose a different option.
- This tool executes pipelines; Pentaho separates them. Analysts using PowerBI to create reports; don't write in SQL. PowerBI couldn't directly suck data from MySQL. Approach was crashing machines of end users; and it became clear that PowerBI was going to be what end users were using to review analytics. PIH added a MySQL to MS SQL-server bridge since PowerBI can consume data from SQL-server directly.
- Is the goal to calculate some fairly standard metrics or do they vary from site to site? They vary and there data analysts who are not SWEs but know how to use data, e.g., through SQL. They may have custom needs.
- Another source of variability is minor differences between different OpenMRS implementations.
- FHIR:
- Requiring FHIR would be a big concern because not useable/friendly enough for end-user Analysts.
- No way the users of their analytics tools would be able to write a query like this:
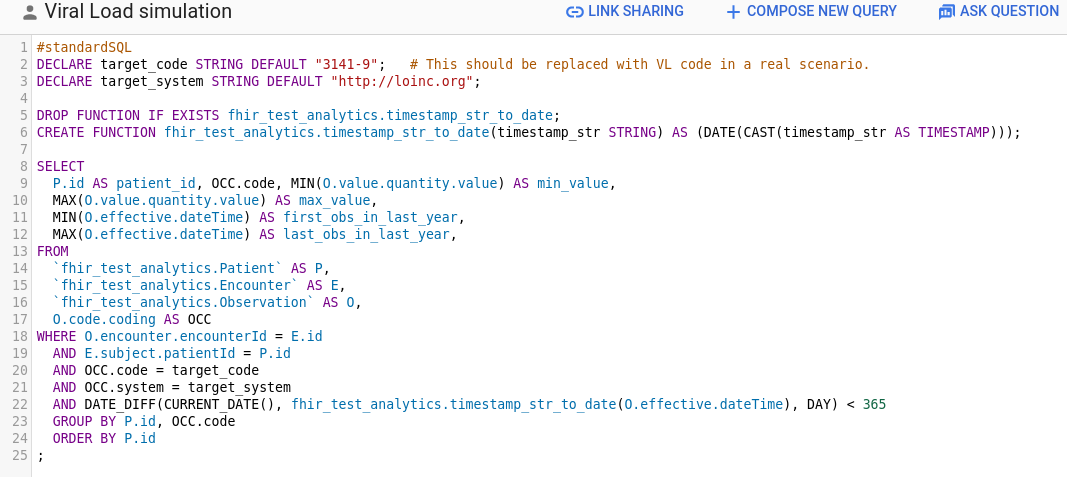
- But we need some middle schema anyways, can that middle schema be FHIR? Potentially, yes. It also depends on the adoption of things like SQL-on-FHIR.
- There is an agreement that if we want the middle layer to be flexible enough to do various analysis, its data model and queries will be inherently complex.
- The current main pain points:
- How to get data out of OMRS; currently it is through cron jobs that recreate data warehouse tables from scratch. Incremental support is definitely useful.
- Dealing with OMRS data model is not easy.
- Is the current PowerBI system work on a single machine or a cluster? How many patients and observations are we talking about?
- Yes, PowerBI runs on a single machine.
- One of PIH's bigger installations has ~400K patients and ~40M observations.
- People want to be able to drill down to actual data, so just providing the target metric is not enough.
2020-07-16: Identify considerations for squad success
Attendees: allan kimaina Bashir Sadjad Ian Bacher Jennifer Antilla Grace Potma
- Need for a separate non-MySQL platform?
- Might be fine when you have small, single sites; but when you want to do data analysis on all them, you need a data warehouse where a single MySQL approach won’t work
- Bashir developing things beyond MySQL already - but do we really need a non-MySQL-based solution?
- Work of squad could be just to write those scripts
- Aim: Not to be locked-in to MySQL. GSoC project working on support for Postgres b/c right now other groups having to install MySQL just to run on OMRS
- Unclear: How possible is it to have a solution that runs across different SQL servers? (SQL supposed to be a standard but reality is it gets implemented differently across multiple vendors → problem for OMRS)
- Posed these questions in Bashir’s FHIR Analytics Google Doc
- Calculations of concepts in background end up causing headaches - this ETL approach doesn’t scale @ Ampath; KenyaEMR have similar experience
- Takeaway: Not going to be a single MySQL approach, because this doesn’t scale and doesn't address the issues IN’s have already run into
- Final output and its usage
- People used to writing SQL - need a tech that someone in M&E/Data Science can simply write SQL to generate a report
- Requirement: Whatever we do, ppl need to be able to run SQL on the solution
- Spark? Hive? Others from Hadoop+?
- Small deployments (10’s of clinics) - should be easy for them to use in single processing environment (on device on location); shouldn’t assume everyone knows how to bring up a cluster w/ 10’s of nodes
- Output could be a MySQL DB
- Requirement: Whatever metric is required, there should be support to drill down further, all the way down to 1 record (easily able to go down to pt records)
- E.g. “Aggregate the # of pts with VL Suppression.” Ppl see # and say “this is an under/over report!”
- Ability to return to MySQL
- Requirement: It should be easy to use the data from within OMRS (exposing the data in OMRS should be easy)
- Quickest way is through MySQL. But exporting data back into MySQL can become a bottleneck
- Module could be the reporting module, tweaked to be able to work with this.
- Requirement: Data in warehouse should be de-identified
- Feature? Issue is compliance.
- Alternative: Access Management
- Deployment requirements
- MVP Requirement: Runs on single node
- MVP+ Requirement: Runs on multiple nodes
- Everything should just work regardless of how many VMs (single or 10’s) - does not require/assume cluster management. E.g. shouldn’t expose dataflow clusters to end users
- MVP Requirement: Provide simple notebook with examples on how to use, query, specific transformations
- Don’t assume ppl know how to run spark cluster or connect data to mySQL DB
- Others working on ETL: UW+I-TECH, Mekom, PIH, etc.
- I-TECH: Meeting w/ Jan & Tracy (to work on I-TECH’s ETL work)
- Mekom: DB Sync work - separate binary that syncs multiple OMRS deployments
- PIH: Mike & Deb & Mark re. How they’re using COVID19 as case study for ETL pipeline
- These are the ppl to regularly engage with when we set up squad (even if all they do is attend weekly squad meetings to give feedback & contribute)
- Team/work/processes etc.
- Clarify purpose as prototyping (it’s unknown what final tool/product will look like)
- E.g. weekly vs q2 weeks, with open collaboration session other week
- Sprint structure
- We use Talk to ____
- We use Slack to ____
- Centralized server with unified sample dataset that we can use to do development and analysis
- Cloud vs On Premise
- Requirements of external agencies - e.g. @ Google all OS forked repos must live under a Google Org (would hurt visibility)
- Bashir to f/u at Google.
- Intro of Technical Leads
- Our prototype goals
- How often we meet
- Where we collaborate digitally
- Data environment
- Any other role clarification
- Work tracking process (Bugs, tickets) while working towards prototype?
- How we consolidate our code, code review process & how we expect this to change over time; expectations for merge/release frequency
- Address nuances contributors are working with
- Decision: Best if everything we develop lives under OMRS.
- Time offering
- Rules of thumb we’ll follow for decision making
- For reference: Decision Making Playbook
- Who has decision making authority
- What to do when lack of consensus is blocking forward movement
- Champion sites (these would be the people who'd use our outputs when we release them)
- Main champion site at this point = Ampath b/c they have biggest DB (& Allan’s expertise!) - able to say “with a DB this size, we can run these obs and metrics successfully” so it should work for smaller sites
- Elevator pitch: Solution that shortens the time and improves the quality of using OMRS data in indicator reporting, reduces unplanned technical team member overtime, and makes it easy to drill down to patient-level data to confirm the numbers are correct.
DONE: Grace post announcement on Talk w/ Doodle; Grace combine requirements into Requirements page.
Directory
Helpful Links
To Address Next Meeting
- Going through SQL vs DataFrame based queries in Spark
- Decide which way people prefer for indicator implementation (and other feedback)
Meeting Notes
2021-04-29:
Want to hear from other people; open new perspective. Without having a dedicated Product Manager, need reps from other teams to bring their problems and efforts to address. Otherwise without PM, dev leads can't take on burden of going around and understanding others' problems.
- PIH
- Using YAML and SQL to define exports that pull data from OpenMRS to a flat table that PowerBI can use
- OHRI - UCSF
- COVID
Ampath run updates
Dev updates
...
AES has (to date) been the combination of three organizations/projects working together on an analytics engine to meet their specific needs:
- AMPATH reporting needs
- PLIR needs
- Haiti SHR needs
MVP
- System that can replace AMPATH's ETL and reporting framework
TODO: Mike to create an example of "if we were to create a flat table, how would that look"
2021-04-15: Squad Call
https://iu.mediaspace.kaltura.com/media/t/1_80xjwir1
Attendees: Debbie, Bashir, Daniel, David, Burke, Ian, Jen, Allan, Natalie, Tendo, aparna, Mike S, Naman, Mozzy
Welcome from PIH: Natalie, Debbie, David, Mike
- M&E team get a spreadsheet emailed from Jet.
- Issues with de-duplicating patients.
- Datawarehouse created for Malawi being redone.
- Recent projects have taken different approach - M&E teams analyze the KPI requirements, adn then design the SQL tables they'd want, then they do an ETL table to have exactly what they'd want for PEPFAR reporting and MCH reporting.
- Past approach was too complicated; didn't promote data use.
Details of past situation
- Previously you'd go into OMRS and you'd export and download an Excel spreadsheet. Exports started to be more and more wrong. Wrong concept, or new concepts added that weren't reflected in exports; people lost trust. To see how things were calculated was very opaque.
- 7 health facilities into one DB; another 7 into another DB; then the 2 DBs merged together in reporting (which is done on the production server of one of those sets b/c there's not a 3rd server, but a new one is being set up for reporting.)
- They were hoping to set up on Jet but seems proprietary, expensive, and old; starting hosting clinical data in this 2 yrs ago. Started pulling in raw (or flattened?) tables - patient tables, enrollment tables. Pull those into the Jet DW
- COVID started and they also weren't able to travel to sites to do training on Jet.
- Switched back to Pentaho & MySQL - used before, open source. Hired 2 new people on Malawi team who were comfortable with that tool and could build their own warehouse in there.
- Main need: 1 table per form. So however concepts organized into a form, needs to make sense as a table unit. Each form - 1 table.
- Would like to add things like enrollment, statuses.
- Why? Forms = intuitive unit; indicator calc usually like obs at last visit,
- 80% Doesn't usually require cross-visit info
- KEMR similar - created a table to automate 1 tbl per form
- Previous tables were extremely wide because it was all the questions we'd ever asked. Would cut that up into multiple tables.
- PowerBI dashboards will be connected to these 1-form tables.
- Volume: Malawi: 50,000pts, a few million obs. Haiti: 500,000-1m, 10's millions of encounters, x4-5 for obs.
- Time: 5-10 mins to run. But in some other servers it's longer and a barrier, e.g. over an hour and increasing by the day - so that's why they're moving away from full DB flattening to one that's more targeted based on what data you're looking for.
- Ultimate Goal: Anything that makes it easier, esp. for local M&E people, to get their hands on the data and make the reports, is great. Easier access, and automation that reduces the workload of local M&E.
Overview:
- Targeting Ampath, because: 10's of clinics supported in a central DB. Has a complicated ETL system that doesn't scale very well, complex so few people understand it, and where the data came from is too opaque to instill sense of trust; want to replace it. M&E team needs flattened data. Want to flatten data into analytical tables that can be converted into tables like excel that they can run their own reports on.
- next, want to try supporting someone who is distributed, and then centralize the data.
- Design goals:
- Easy to use on a single machine/laptop. Whole system can be run on signle machine.
- ETL part: 2 modes of operations, batch mode and streaming mode.
- Reporting part:
Questions
- if you have any other questions for what might be useful for an M&E/Analytics person please email me at nprice@pih.org
- What are the best ways forward for PIH to try this and apply to some of their mor challenging use cases? E.g. local M&E teams not showing analytics of things happening over time
- Follow up to figure out how to create the FHIR resources...
2021-04-01: Squad Call
Attendees: Bashir, Moses, Tendo, Burke, Daniel Ian
Regrets: Allan, JJ, Grace P, Cliff
- Bashir: working on date-based filtering, as a way to get data only for "active" patients within a date range (e.g., all data for "active" patients within the past year)
- Given a list of resources and a date range, we pull all dated resources within the date range
- For all pulled resources that refer to a patient, we pull all data for each patient
- Moses: working on a blocker, inability to pull person and patient resources for the same individual in the same run (#144)
- Tendo: working on implementing media resource, working through complex handler
- Cliff (in absentia) working on running system via docker command
- Skipping meeting next week due to OpenMRS 2021 Spring ShowCase
2021-03-25: Squad Call
Attendees: Bashir, Allan, Cliff, Daniel, Ian, JJ, Allan, Ivan N, Willa, Grace P
Recording: https://iu.mediaspace.kaltura.com/media/t/1_msvydoso
Summary:
1. Decision: New design for date-based fetching in the batch pipeline, based on active period (for each patient "active" in care, all the resources will be extracted). We defined an "active" period (the last year), and break down the fetch into 2 parts: (1) any obs from the last year, then (2) for each patient with a history in the active period, all of their history will be downloaded. Why: Avoids search query time-out problems.
2. Later: Add ability to retrospectively extract resources back in time (re-run pipleline for any time period) in order to update your datawarehouse.
Updates:
- Bashir: Close to fix for memory issue; working on date-based
- Allan: Trying to finalize orchestration of indicator calculation. Implementing using docker & docker compose. Streaming mode.
- Antony (regrets): Working on list of indicators that need baseline data.
- Cliff: Streaming mode script. Refactoring in batch mode.
- Mike: Experimenting with approach, more updates next week.
Current plan for implementing date-based fetching: Getting the data when you need it, not all at once.
- Implemented on FHIR search base path. 2 modes for batch: pipeline JDVC mode, and FHIR search base.
- First step allows qualifying "I need last year"
- List of pts who've had >=1 obs in last year
- Second download, we download all of the resources going back.
- This will avoid the search query time-out problem we ran into in past. Idea is to download small batches in parallel.
Concern raised by JJ:
Approach needs to be able to handle queries that involve all patients, and need to be able to prove findings (i.e. can't simply use an aggregate deduction model, because you can't show "here are the exact patients" if someone needs to confirm your numbers are correct).
2021-03-18: Squad Call
Attendees: Bashir, Allan, Mike Seaton, Grace P, Christina, Burke, Cliff, Daniel, Ian, Ivan N
Recording: https://iu.mediaspace.kaltura.com/media/t/1_qj4xzv9t
Summary: What do we do with big databases with batch mode (where it's not feasible to download everything as FHIR resources or it will take a very long time)?
Two approaches came out to address the above problem:
1. First approach is limit by date (last week's discussion focused on this)
2. Second approach is to limit by patient cohort (focused on this today; idea is you'd limit queries based on patient instead of based on date, e.g. "Fetch everything for a cohort of patients") → We think this will be a better approach to try out moving forward.
Updates:
- PIH looking for Analytics Solutions, Mike's reviewed ReadMe, interested in trying out. Next: ______
- Bashir: Decision to do date-based separation of parquet files. Planning to go back to the FHIR-based search approach.
- Google contrib Omar: another 20%er from Google who is contributing PRs. Added JDBC mode to E2E tests.
- Google contrib William: still doing ReadMe changes/refactoring and move dev-related things under the doc directory.
- Allan: Instead of using distributed mode, use local mode.
- Cliff: Looking at datawarehousing, & issue of fhir resources in DW.
- Mozzy: Bug fixes so it can be used w/ Bahmni.
Discussion of Challenges:
FHIR structure isn't causing delays, but the conversion of resources into FHIR structure is slowing things down. TODO: Ian to look into improvements that could be made in FHIR module.
2021-03-11: Squad Call
Attendees: Bashir, Antony, Daniel, Grace, Allan, Moses, Tendo, Ojwang, Ken, Jen
Recording: https://iu.mediaspace.kaltura.com/media/t/1_lskh65vm
Summary: Discussed memory problems & performance in Ampath example. Direction we're taking for Ampath: To divide DW based on date dimension. For most of the resources, we don't generate for the whole time, just the last 1-2 yrs. Then we need to support special set of codes, where we generate the obs just for those codes. The set of those obs is much smaller.
- Work Update
- Bashir: Code reviews & investigation of memory issue. Added JSON feature into pipeline since it was helpful w/ debugging.
- Allan: Working to dockerize streaming mode, how to register indicator generation.
- Suggestion from Bashir: Adding more indicator calculation logic would be great.
- Moses: Upcoming PR w/ bug fixes
- Sending too many requests: had been looking at moving to using POST but fetching 100 resources at a time takes a few seconds, and can flood MySQL and OMRS, so doesn't see much value in fetching 1000's resources at a time on a local machine. 90 resources was actually faster.
- 2 other new contributors:
- Engineers at Google can spend 20% time on other projects. Posted some projects a few weeks ago related to this squad.
- Omar working on adding JDBC mode to batch end-to-end test
- William working on documentation fixes; trying to keep README user-centric rather than dev-centric. Anything dev-centric goes to separate files.
- Engineers at Google can spend 20% time on other projects. Posted some projects a few weeks ago related to this squad.
- Memory Issue with fetching encounter resources at AMPATH
- Compile list of IDs to be fetched; send 100-resource-request at a time to OMRS; convert those into Avro, and write into a parquet file. So because there is no shuffle anywhere, should continuously work regardless of the size of DB, and the memory requirement shouldn't increase.
- Investigated:
2021-03-04: Squad Call
Recording: https://iu.mediaspace.kaltura.com/media/t/1_yyg2els7
Attendees: Allan, Bashir, Moses, Antony, Cliff, Daniel, Ian, Jen, Ken, Sri Maurya, Steven Wanyee
Updates
- Bashir:
- Coverage reports added to repo.
- Bug identifying, & fix is out (not generating parquet; adding a flag to set number of shards)
- Fetching initial id list: Realized this isn't being slowed down by FHIR search or JDVC mode. Turns out it was the generation of Parquet - causing order of magnitude slower.
- Beam: Distributed pipeline environment. It's deciding how many segments for the output file to generate. Seems like an issue with Beam, Bashir to report to Beam.
- More Google people expected to start contributing eventually - up to 20 people
- Allan
- Moses
- Antony to follow up with Bashir and Moses to setup on machine & to join Tuesday check-ins
- Apparently there has been some testing of CQL against large data sets with Spark
- Intro from Maurya Kummamuru: Extracting OMRS data w FHIR to perform CQL queries against it. Demo coming at FHIR squad next week Tuesday.
2021-02-25: Squad Call
Recording: https://iu.mediaspace.kaltura.com/media/t/1_fa0o9440
Updates: Substantial bug fixing needed for Ampath pipeline pilot; 2.5hrs for table with 800,000 patients too slow.
2021-02-18: Squad call
Recording: https://iu.mediaspace.kaltura.com/media/t/1_m0rqigrl
Attendees: Burke, Tendo, Ian, Bashir, Amos Laboso, Cliff, Daniel, Jen, Grace, Allan, Mozzy, Sharif
Updates: Focus atm is on preparing for Ampath pipeline pilot release.
2021-01-28: Squad call
Recording: https://iu.mediaspace.kaltura.com/media/1_glpg4zts
2021-01-21: Data Simulation Engine demo, Random Trended Lab Data Generation demo, and How to Use Spark demo
Recording: https://iu.mediaspace.kaltura.com/media/1_q8wr0m9h
Attendees: Burke, Bashir, Antony, Cliff, Daniel, Ian, Jacinta, JJ, Juliet, Justin Tansuwan, Piotr, Steven Wanyee, Grace
- Data Simulation Engine: Ian demo
- Engine that generates random patients and random VL values for them. E.g. simulation that runs for a time range of 5 years, to show people coming in and getting lab tests over the course of 5 years of visits:
- Built using data like LTFU, % of pts with a suppressed VL
- Steps through every simulated day and outputs a file
- Generating Random Lab Data: Grace/JJ demo
- Colab Notebook: https://colab.research.google.com/drive/1EMiAkbhW7TzEVlFRfUGFPIpBSgZ6GmSX#scrollTo=Uk-W16jgSf-f 5 min Demo Video: https://www.loom.com/share/ed62dc728e46401894a5cdc57ef28bd3
- Running through the Notebook generates and POSTs random, bounded, trended lab data over time. Example demo'd: Posting 40 Viral Loads
- How to Use Spark: Bashir demo
- Goal is to provide APIs over time to get base representations of the data that's being stored in FHIR for now. Bashir trying to show how this can flatten and remove the complexity of FHIR from what the person needs to understand to run the query.
- Changing stratification and time period could take minutes to an hour. E.g. when a PEPFAR Indicator requirement
2021-01-14
Attendees: ?
Top Key Points
- Discussed the question of whether to use SQL or Python to develop indicator logic and decided to use Python.
- Discussed how Spark deployment will be done and decided to focus on the local version (with many cores) for the time being.
2021-01-07
Attendees: Reuben, Ian, Burke, Kaweesi, Cliff, Jen, Allan, Bashir, Patric Prado, Kenneth Ochieng, Grace Potma
Top 3 Key Points
- Our Highest Priority Q1 Milestone: To continuously be running beside the current indicator calculation AMPATH is using, and to show they generate the same indicators
- Other Pressing Milestone: A second implementer - esp. one with multiple sites who want to generate analytics by merging them.
Notes:
- Updates: Bashir now moved from Google Cloud team to Google Health. Opens opportunity for him to continue contributing to OMRS for a few more quarters. OMRS has been given $5k in AWS credits; however, Google Cloud could have ~$20k available if we need it. Question is not "what to do with those credits" but "what do we need".
- E2E test progress: 1 component to each that hasn't been merged. First was test for being able to spin up a container - done.
should eventually support multiple modes (e.g., Parquet vs FHIR store, batch vs streaming); we can add them gradually.the last component to e2e
- Large data set: Ian working on simulator for this (takes time to work w/ realistic data!)
- 2021 Q1 Goals
- Main Goal (Highest Priority): To continuously be running beside the current indicator calculation AMPATH is using, and to show they generate the same indicators. Next steps: Implementing those 10 reference indicators.
- Other Goal: A second implementer - esp. one with multiple sites who want to generate analytics by merging them.
- Who to reach out to: PIH, Bahmni (JSS), Jembi, ITECH (iSantePlus in every hospital in Haiti - Piotr has been involved in analytics work b/c they're looking to aggregate data into one store)
- Value Prop: If you have multiple deployments and find that managing indicators takes repeated headaches to maintain - this is for you. You can get your indicators with little maintenance, and it should work at scale. If you have many sites, many patients, many obs, this is fast, will enable interactive queries that don't impact your production system performance. The beta is early so your feedback and your org's needs will allow the squad to ensure what we're building is applicable to your use case.
- Key points from 2020 Retrospective: https://docs.google.com/presentation/d/1f0VFO0eucWZYpIDOtm8smcCNWdW_7YjdhBWS7bdfTJ8/edit#slide=id.gb1d91779dd_0_733
2020-12-18: Squad Call: Retrospective, Summary of What We Accomplished in 2021, and What We're Doing Next
Recording: https://iu.mediaspace.kaltura.com/media/1_8xg6i7yd
Summary: Thank you, everyone, for making some of this squad's objectives a success. We have made quite a significant milestone and hope to see great results come 2021. For those who could not join our last 2020 meeting, take a look at the retrospective and roadmap. Feel free to add to the list or upvote any item. Also here is the slide containing a summary of the retro and the accomplishments so far: https://docs.google.com/presentation/d/1f0VFO0eucWZYpIDOtm8smcCNWdW_7YjdhBWS7bdfTJ8/edit?usp=sharing
2020-12-10: Squad Call
Recording: https://iu.mediaspace.kaltura.com/media/1_4sqok6f1
Updates
- Allan -
- Piotr - setting up test sync via docker w/ HAPI FHIR server example to stream to. Reverting back to R4; only using R3 for buntzen part of pipeline. Currently doesn't incorporate a number of the fixes he made to the atomfeed client.
- Ian - generating some test date (goal is to finish January); Allan to follow up with statistics on variables
- Cliff - end-to-end test for changes (moving debezium settings to an adjacent file), PLIR: working on an e2e test for the changes made to enable the hapi fhir JPA support basic authentication
- Moses - connecting to OpenHIM with FHIR2 module work; presenting today
Topics
- ReadMe file too bulky
- Demos
- Moses
- Video of OpenHIM Demo:
- Analytics Pipeline High level Architecture Diagram:
- https://talk.openmrs.org/t/my-fellowship-journey-mutesasira-moses/31121/2
- Moses
- Need to continue Spark API discussion
2020-11-24: Standup
Recording: https://iu.mediaspace.kaltura.com/media/1_oj89pvy1
2020-11-19: Squad Call
Attendees: Bashir, Burke, Jen, Allan, Ayesh, Daniel, Ian, JJ, Jorge, Kenneth, Joseph, Sharif, Steven, Suruchi
Recording: https://iu.mediaspace.kaltura.com/media/1_ksxewulx
2020-11-17: Standup
Recording: https://iu.mediaspace.kaltura.com/media/1_yb0q1jsq
2020-11-12: Spark & Parquet prototype demo, and how to query them to generate indicator data
Attendees: Bashir, Ayesh, Brandon, Cliff, Daniel, Ian, Jacinta, Jen, JJ, Kenneth, Allan, Grace, Joseph, Mozzy, Piotr, Sharif, Steven, Vlad Shioshvili
Recording: https://iu.mediaspace.kaltura.com/media/1_dpyhepf4
- Dev Updates
- Bashir - PRs and prototype of indicator calcs plus spark implementation
- Cliff - PRs - moving debezium to DB config; adding javadocs to specs we have in AE code; getting rid of some runners for streamin. PRs wiating waiting for merge:
- Ian - trialing generating stats from Bashir's prototype - script we can plug weights into and it's a matter of getting the %'s right (in R)
- GitHub repo for weighted scripts coming
- Allan - to share more comprehensive statistics; had to make some changes recently
- Piotr - End to End testing the PR for HAPI FHIR communication with Sync: batch and atom feed streaming approach; ongoing issues w/ end to end FHIR tests; set up w/ Docker but atomfeed not installing on it due to liquibase problems. Transporting resources with a summary tag to HAPI FHIR server → HAPI FHIR server was not allowing resources with a summary tag to be saved; had to remove the tag to send.
- Jacinta
- Working on the end to end test for the pipeline
- Todo
- Switch from using OpenMrs nightly image to latest which is stable
- Piotr requesting addition of atom feed module
- Re-generade Demo Data
- Steps to generate demo data:
- The steps for generating demo data are documented here: Demo Data. It’s basically a matter of setting a single global property and restarting an OpenMRS instance. And then waiting
- Prototype Demo: Implementation of Indicator Calculation
- Why Parquet: Benefits of using Parquet
- Columnar format: Using parquet files because of columnar format - can go through those columns without actually fetching those records. Huge difference to other systems. Parquet is an open source version based on Dremnel which was originally an internal Google tool.
- Considers distributed environment: When you have huge amt of data you can't store on a single machine. You shard file into many shards, that can be distributed across many different machines.
- If you have 10's of workers - they can filter out the data they have, and just fetch the records that are of interest for our query. So you don't see benefits when running locally, but you do when it's distributed.
- Compression:
- Apache Arrow: Apache uses this internally to represent parquet files
- Why Spark
- Map-Reduce efficiency: typicaly map, shuffle, reduce- most of the intermediate steps involve writing to disk. With this approach, things go 10-100x faster than a usual map-reduce.
- PySpark = Python API to spark; so this demo is mostly Python. Can also create Jupyter notebook that talks to PySpark (Bashir just isn't doing it that way yet).
- Think Locally and still be able to scale: You submit your query to spark. Beauty = the same thing (the spark - submit sample indicator) can be sent to a distributed cluster - means you can think locally, but continue to run when you scale to a distributed setup. Can use this exact same command to run on local or on real Spark cluster.
- Example: Looking for Codes
- Option #1: Write query with SQL code and FHIR:
- Can structure indicators with FHIR codes. Someone who knows FHIR and knows SQL - it should hopefully be easy for them to write these queries
- Option #2: via Python querying Spark API
- Using Python to query Spark dataframe which is seamlessly distributed on multiple machines
- Can just focus on columns of interest:
- Pros/Cons of the 2 Approaches
- Performance: SQL query may have done better; unclear b/c small test set size
- Learning Curve: Spark API took 2 days to learn how to query their API.
- Readability: with SQL, clearer to see if you're calculating things correctly. SQL is more likely to be readable/familiar.
- Maintenance: Spark API query more maintainable than SQL query as your queries grow. E.g. creating an API into our own server to query indicators could save time longer term.
- TODOs
- More feedback next week
- Slack discussion on Option 1 vs 2, and Python vs Java
- Create Google Cloud infrastructure a some kind of notebook to query it
- Why Parquet: Benefits of using Parquet
2020-11-10: Standup
Recording: https://iu.mediaspace.kaltura.com/media/1_km9wjf5z
2020-11-05: Squad call
https://iu.mediaspace.kaltura.com/media/1_xwiwud01
2020-11-03: Standup
Recording: https://iu.mediaspace.kaltura.com/media/1_52jeny9e
2020-10-27: Standup
https://iu.mediaspace.kaltura.com/media/1_jm4887sf
2020-10-22:
Recording: https://iu.mediaspace.kaltura.com/media/1_0f2p04pj
Attendees: Allan, Bashir, Burke, Grace, JJ, Suruchi, Daniel, Ian, Jacinta, Jorge Quiepo
Welcome to Suruchi, sr dev from NepalEHR with interest in implementing analytics engine at their implementation, and new OpenMRS PM/Dev Fellow.
Reminder: Squad Showcase next week
Dev updates:
- Bashir has been working on simplficiation of camel
- Allan
- Converting atom feed config service logic
- Performance assessment of batch (patient, obs, encounters)
- Needs to add additional FHIR resources
- Bashir command line flag - can specify resources + search (this is because batch mode built on top of search api)
- OpenMRS Docker file has problems - liquidbase migration is happening despite update_db setting at false
- Jacinta
- New to squad from AMPATH
- She will be taking over issue of docker file https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics/issues/38
- Also will take on issue of creating an integration test : https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics/issues/8
- Moses
- New to squad, looking for opportunities to work on PLIR
- Working on config issues related to R4 and R3 via atom
- Use HAPI FHIR client to load resources into generic Bashir - https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics/issues/29
2020-10-15:
Attendees: Bashir, Grace, Cliff, Daniel, Ian, Jacinta, Juliet, Allan, Mozzy, Piotr, Sharif, Vlad, Jen, JJ
Recording: https://iu.mediaspace.kaltura.com/media/1_h7p70dss
Dev. updates:
- Piotr - finishing up my couple of PR by next week, on the streaming docker setup and HAPI fhir client use
Addition of 2 new devs to team
- Moses Mutesa - fellowship mentor
- Cliff - volunteer
MVP Progress
- Want to have a way to transform data from an OpenMRS intance, in batch and streaming modes, trans data into FHIR that's easily converted into Spark, so that we can run queries at scale.
- Success metric: When we can run FHIR queries on spark at scale.
- Batch issues have been resolved and can create in Parquet.
- In a few weeks, how much to focus on original 10 PEPFAR metrics, given current CQL discussions? Can expose Metrics API that can be consumed. More updates to come from Vlad in next 2-4 weeks. If we integrate some of their work, means we'd be able to map to ~15 indicators.
What's the next step for getting from FHIR to indicators?
- (1) Next 2-4 weeks, focus remains on getting FHIR queries to run in Spark at scale. Getting engine running (as opposed to just a few metrics) - once that's running, (2) try implementing the example list of metrics, (3) look at whether there's an automated way of handling metrics like those examples in the future.
- Squad needs to focus on (1), the mission-critical groundwork.
- Summary: Datasource: OpenMRS. Tool to get it over: Parquet. Structure: FHIR. ETL Query tool: Spark. Means analyst can set up workspace to run ad hoc queries quickly at scale that run in seconds without impacting production. (E.g. every patient that visited my clinic within the last few months with HIV) Future: To be able to use other analysis/warehousing tools, more work to do.
Ampath example: SQL scripts generate report values. E.g. How many patients are on ARV: Take QID 123 and QID 345.
So - is it fair to assume that almost everything else but the concepts is the same? This is why Vlad's mapping tool is of great interest. Users need to be able to back up through the logic to show the result can be trusted.
How do we represent those SQL case statements? Can add logic into your FHIR module. E.g. my unified viral load concept
Ian investigated how TX_PVLS was calculated in 3 different implementations. All 3 were using slightly different definitions, even when using the exact same concepts. Some stored as obs, some stored as orders.
How PLIR/Notice D work is Different
- Indicators calculated in OpenHIM; focus is on passing FHIR resources through
- Prove extraction of the relevant dataset in the right format
Who's doing what next?
- Demo for implementers at next Squad Showcase
- Examples of a few calculations - Ian?
- JJ to share SQL case statements with Vlad & Squad
2020-10-08: Presentation of Analytics Engine approach and work so far & FHIR background
Recording: https://iu.mediaspace.kaltura.com/media/1_4ievjc2p
Attendees: Allan, Bashir, Burke, Ashtosh Padhy, Cliff, Daniel, Kenneth, Michael Gehron, Vlad Shioshivili, Ivan N, Piotr, Suruchi, Tendo, Ian, Juliet, Moses, Sharif
Overview presentation of the Analytics Engine Squad's work so far, & discussion with Michael & Vlad from PEPFAR PLM team.
- Emphasis from squad on performant solution that can handle large quantities of data - this drives our architecture decisions. Planning to access info through a Metrics API.
- FHIR was chosen as the API for talking to OMRS. FHIR is also the main data model for the Analytics Engine to benefit more from standard tools built on top of FHIR.
- FHIR2 module/bundle can generate FHIR resources, so Analytics Engine can rely on that; default information model is FHIR.
- The fhir2 module is currently a series of translators that transform into FHIR. Long term hope is to replace stuff we're storing in custom OMRS formats with FHIR, so we speak FHIR natively. Goal of module for now is to transform 80% of that custom OMRS data into FHIR.
- The FHIR2 module update recently released: Reading the vast majority of data in OMRS - can read patients, orders, conditions; some writable parts of API still WIP.
PEPFAR logic changes happen so frequently, so the PLM work is aiming to include a logic model that they (PEPFAR?) would keep up to date so implementers could just reference that, and not have to each go through the massive work of logic updates.
2020-09-24
Present: Vlad Shioshvili, ALlan, Bashir, Christina, Daniel, Burke, Ian, Ken O, Michael Gehron, Tracy, Grace, JJ, Jen
Recording: (PEPFAR PLM demo starts 14 minutes in) https://iu.mediaspace.kaltura.com/media/Analytics+Engine+Squad/1_4759yb4v
Agenda:
- Discussion on CQL and PEPFAR metrics.
- Update: Progress with FHIR schema and Spark - not done; next time
- Update on overall Squad progress: the analytics squad has created prototypes for extracting data using FHIR in both batch and streaming modes. However, we have not done any work on indicator transformations/aggregation
- Decision: Decide btwn Debezium embedded and Camel Debezium - plan was to use Debezium directly, but Allan has done some tests and Camel seems like a better idea - so this PR is going forward.
- PR for adding basic auth (username/pwd) from Piotr.
@Vladimer Shioshvili continued the presentation on PEPFAR's Patient-Level Monitoring for M&E Proof of Concept as well as gave a live demo. Slides: https://docs.google.com/presentation/d/1t9astN7NboSycFax0vNgZxVJ2Tc6OJF3_3HJaJGGAIM/edit
- Questionnaire resource mapped to FHIR - collects questionnaire responses which are also mapped to FHIR.
-
Working with IntraHealth on integrating the openclient registry to reconcile the patients across different point of service applications. So when they receive messages from multiple systems, want to make sure one person is indeed counted as one person. A lot of times, false positive LTFUs happen because of a transfer of a patient to another system, that didn't get captured as one patient moving.
Looking to use CQL instead of custom agreggations they have written right now.
Should be able to share Repos within a couple of weeks.
Next Steps:
- ...
2020-09-17
Agenda:
- Demo from group from OpenHIE's Data Use Community (DUC) who want to generate MER indicators on FHIR
- Update: Progress with FHIR schema and Spark [next time]
- Decision: Decide btwn Debezium embedded and Camel Debezium [next time]
2020-09-10
Present: Allan, Bashir, Burke, Daniel, Debbie Munson, Ian, Jen, JJ, Juliet, Mozzy, Sharif, Tracy, Grace
Recording: https://iu.mediaspace.kaltura.com/media/1_gkdr9uvr
- Announcements
- Product Management update - JJ Dick will begin co-leading Product Management of the squad with Grace
- Call timing update - please do this poll: https://doodle.com/poll/hy8ekhwxy9n3m7ck so we can make this call accessible for more people
- Other announcements or work people would like to update the squad about?
- Allan: to demo his progress
- Takes < 3 mins to extract 3,000 datapoints from ~500 encounters; tested with encounter and obs
- Asks a lot of the FHIR2 module for performance (current focus of FHIR squad has been resource mapping, not performance, yet); could be further optimized
- Allan suggestion: People should be able to extract the data however they want, but FHIR as the preferred/recommended mode
- Next steps: How can we move forward and get work done together?
- Schema Talk Thread: https://talk.openmrs.org/t/to-schema-or-not-to-schema-deciding-on-a-foundation-for-our-analytics-engine/29953/11
- Problem: Need to have flexible engine, for where FHIR won't help us (e.g. where a new table cannot be mapped to FHIR, or you have a separate labs DB which you want in your analytics warehouse where you can query it). For Ampathy, FHIR will work ~80% of the time, but may not work all the time. So: Do we want to go for schema or schema-less warehouse?
- Allan's recommendation: Support both - FHIR as main schema, and have flexibiltiy to store data, have your analytics engine access that
- Bashir: For first prototype, use SQL on FHIR. You can still bring any type of data into the warehouse that's not FHIR. Current prototype uses FHIR API to pull the data. Eventually we could bring an extension into the pipelines that creates a view, brings the data forward anyway. Once you have custom data in your warehouse that you want to use for analytics, then by definition, you have to use custom logic anyway.
- Burke; FHIR not ubiquitous enough, don't want to lock ourselves in.
- Mapping to FHIR is not a requirement.
- Decisions
- Agreement: We're moving forward with at least FHIR.
- What's next? Try moving forward with Spark.
- Debezium? Discuss next time.
- New meeting time: Thursdays at 2pm UTC
- TODO: JJ to intro squad to other group from OpenHIE's Data Use Community (DUC) who want to generate MER indicators on FHIR; try to get them to demo next time
2020-09-04
Recording: https://iu.mediaspace.kaltura.com/media/Analytics+Engine+Squad/1_iw9pijl5
- Kenneth Ochieng (Intellisoft) shared work for DS Notice D as proof of concept system for integrated approach to patient-level reporting
- Using Bahmni for point of care system
- Using Bahmni's Atom Feed Module to expose data
- Sending patient data using FHIR format to OpenHIM
- Storing FHIR data into HAPI FHIR server within HIE as shared health record (SHR)
- Using FHIR Measure resources within HAPI FHIR server
- Will use CQL engine against HAPI FHIR server to calculate measures and share them with DHIS2
- Defining development process
- Making decisions: use Decision Making Playbook
- Slack channel: #analytics-engine
- Handling tickets
- Consider using github during prototype stage
- May re-visit and consider JIRA once a shared approach & repo(s) has been decided
- Repository
- Handling Pull Requests
- Would like to have a server within OpenMRS for testing (e.g., ae.openmrs.org for "analytics engine")
- Large demo dataset is ~200 GB
- At least 8 GB (16 GB would be preferable)
- Could repurpose sync servers
- Making decisions: use Decision Making Playbook
- Make the call about data store and general structure/approach.
2020-08-28
Recording: https://iu.mediaspace.kaltura.com/media/1_zo38ckft
- Discussion on the road-map; request for feedback
- Schema selection choices and flexibility
- Schema evaluation (e.g. OMOP, SQL; is no-SQL approach possible?)
- Discussion on talk: To schema or not to schema… deciding on a foundation for our analytics engine
- allan kimaina considering use of Apache Parquet as initial format for data
- How to process data?
- We have a bias toward Apache Spark
- Tools for handling data workflow
- Delta.io is a tool allan kimaina has been evaluating
- Apache Beam was suggested by Bashir Sadjad
- Bunsen is an interesting tool backed by Cerner that allows
- Would like to aim for initial examples
- Using FHIR Data for a PEPFAR report using FHIR
- Use a custom datatype in early examples to demonstrate that the pipeline is not FHIR-only
- CQL support
- CDC seems to have a preference for PowerBI - we can expect this to be a priority use case (exposing or transforming data into a format that PowerBI can use)
- Stretch goal: Running PythonNotebook on top of data
Action: Make the call before or by next call about data store and general structure/approach. allan kimaina & Burke Mamlin owning follow-up.
2020-08-21
Recording: https://iu.mediaspace.kaltura.com/media/1_rxkt7fss
Attendees: allan kimaina , Bashir Sadjad , Burke Mamlin , Ian Bacher , Jennifer Antilla , Juliet Wamalwa , Kenneth Ochieng, Piotr Mankowski , Tracy, Grace Potma
- Dev. updates
- Batch implementation pushed to same GH repo. Demo'd recently to FHIR squad. https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics
- Piotr working on dockerized version of streaming app to synchronized between an OMRS and HAPI FHIR instance
- POC needed in 6 weeks - so Piotr working on getting atomfeed solution cleaner/simpler
- Review of MVP goals
- OMOP/schema feedback
- Presentation from Alan:
- Proposal: Use FHIR as intermediate
- Discussion: How to approach building FHIR schema to prepare for other use cases that would otherwise be forced to create their own pipeline/engine if they don't use FHIR
- Need to support other formats as well
- Discussion on Talk: To schema or not to schema… deciding on a foundation for our analytics engine
- Presentation from Alan:
- Proposals for issue tracking, code location, and code review (TL;DR; GitHub)
- Agreed on using GitHub for issue tracking in this squad
- Bashir on Vacation next 2 weeks
2020-08-14
Attendees: Antony, Burke, Allan, Bashir, Christina, Daniel, Debbie Munson, Jayasanka, Jen, Juliet, Tracy
Recording: https://iu.mediaspace.kaltura.com/media/Analytics+Engine+Squad/1_7yw4tayq
- Welcome!
- Antony (Palladium), Debbie (PIH)
- Announcements
- Awesome job on Squad Showcase!
- Did you notice we're now Analytics Engine Squad? For example, our zoom call shortlink is https://om.rs/zoomaes
- Renamed #etl Slack channel to #analytics-engine to reflect this
- Dev. updates
- Bashir: Code for monitoring changes, transforming data later into a FHIR resource. Opensourced now https://github.com/GoogleCloudPlatform/openmrs-fhir-analytics
- Location: Google Cloud Platform for now while still getting started. Apache License. Can go to OMRS if that's a better place in future.
- Please check it out!
- Allan: Evaluating w/ Cornelius (Ampath FHIR expert) - went through data tables. Found 70% of Ampath data represented w/ FHIR; what about other 30%? Looking to expand that.
- To use FHIR as intermediate storage, we definitely need a custom schema that covers that other 30%.
- Challenge: How to limit this so people don't depend too much on custom schema. This wouldn't realize the benefit of the entire pipeline.
- Some implementers not comfortable with FHIR - this would enable them to use custom schema. But, adds scope: Requires us to support two schemas.
- Bashir: Code for monitoring changes, transforming data later into a FHIR resource. Opensourced now
- Continue discussion on data warehouse schema:
- Still need to discuss schema. E.g. OMOP.
- API to access schema? At Google, history seemed to be SQL was trusted, i.e., SQL as an API for accessing data. The context is BigTable to SQL based APIs migration.
- At the end of the day, the query complexities are still there, even if we pick a non-SQL API.
- For end-users: Agreed that consumers need to have tooling at the end that allows them to get the data out - even without knowledge of SQL.
- For under the hood - Schema Flexibility: Concern around committing to relational database approach if we don't have to
- Nice because people can bring whatever they want
- Hard because it will be harder to build things on top
- E.g. Palladium: does development, other players consume data. Need frameworks that empower those users to come up with their own reports. So many funding agencies that all have their own reports (e.g. CDC, USAID, DOD), have different report requests at least every week! Need to be readily consumable for ad-hoc reporting. Where everyone understands queries for what's in the system.
- Being able to perform ad-hoc reports could be an argument for SQL
- Not clear that OMOP has wider adoption than FHIR. Well adopted in clinical research community.
- Keep researching/asking? Or just start with FHIR?
- Using FHIR for data analytics tools is already happening. Unclear: Are people widely comfortable with OMOP? Easier to work with. Primarily designed for de-identified data.
- We always have the option for FHIR→OMOP in future as there are open source tools for that transformation.
- OMRS quite involved helping set up OHDSI community
- FHIR background is to support both data structure for SHR and for analytics
- Where do we go from here?
- TODO: Allan to review OMOP
- TODO: Grace to set up meeting w/ Squad & James/Carl re. ADX/OMOP advice
- TODO: Burke to start Talk conversation around initial schema (w/ link to Analytics on FHIR)
- Still need to discuss schema. E.g. OMOP.
- Concrete MVP goals:
- Single machine pipeline, while easily scalable (note on MySQL bottleneck)
- Horizontally scalable warehouse
- Metrics API with a minimum set of indicators
- Implement the 10 common indicators; show people how quickly they can be calculated. Idea is this could be a separate module that uses the warehouse.
- Deploy as docker image; they get an end point they can query to issue queries to underlying data. But has to be scaleable. OMRS itself not horizontally scalable. MySQL would be the bottleneck for scalability in the data pipelines.
2020-08-07
- Recording: https://iu.mediaspace.kaltura.com/media/1_pzweel3o
- Attendees
- Updates
- TODO - Grace set up call w/ James K & squad tech leads
- TODO - Grace consolidate visuals of ETL demos from implementers
- Deidentification of randomized data set ongoing by Allan at AMPATH
- Bashir experimenting with converting data to FHIR resources and pushing to a FHIR warehouse; includes bulk-update. To make open source code available to all next week.
- This code can be used to extract OMRS data as FHIR resources. Generic tool, not just for analytics, even though original use case was to push to FHIR warehouses.
- Review of hot-spots for run times
- Proof of Concept
- Looking for 1+ more site
- Need to i.d. what the intermediate schema is that they're okay with (e.g. some for/against FHIR) - is there any other analytics schema out there that makes it easy to come up with the concepts around it?
- OK to use SQL as main interface? (commitment that end product would be used)
- Need to i.d. intermediate schema, assuming it's not FHIR.
- Just build and get feedback from prototype?
- Do we need separate mechanisms for standardized indicators?
- Need to get to a data warehouse where we can get to those specific features; maybe phase 2 we get to specific querying
- TODO: Tracy to post and s
- Other standardized schema examples: OMOP, I2D2
- OMOP use case suggestion: Different way to transform the data into a standardized format, to have common data for analytics. Another way of trying to do data analytics / warehousing at scale. Advantages is that because it's been standardized as a model, a lot of tools being built against it.
- Existing libraries for converting FHIR→OMOP
- OHDSI: https://ohdsi.github.io/TheBookOfOhdsi/ OHDSI Common Data Model: https://github.com/OHDSI/CommonDataModel/wiki OHDSI Analytics Tools: https://ohdsi.github.io/TheBookOfOhdsi/OhdsiAnalyticsTools.html
- OMOP use case suggestion: Different way to transform the data into a standardized format, to have common data for analytics. Another way of trying to do data analytics / warehousing at scale. Advantages is that because it's been standardized as a model, a lot of tools being built against it.
- Building on REST API FHIR store loses some of the advantages of storing in SQL
- Need to support not-cloud-based: We can provide tools (e.g. Spark), but responsibility of implementers to manage their own cluster if they want scalability beyond single node.
- Would be nice to provide these sites w/ different versions of Docker component files for such cases.
- "Engine"
- Deidentification
- Looking for 1+ more site
2020-07-31: First Squad Call
- Recording: https://iu.mediaspace.kaltura.com/media/Analytics+Squad/1_id8660id
- Attendees
- Burke Mamlin , allan kimaina , Bashir Sadjad , Christina White , Daniel Kayiwa , Dimitri R , Ian Bacher , @Jayasanka, Jen, JJ, Mike, Steven, Tracy
- Introductions
- Technical Leads Allan & Bashir
- Mekom: Keen to include analytic platform in work for clients
- Jayasanka: Working on DHIS2 reporting module, love for analytics/viz
- AMPATH: Have been supporting hacky ETL solution; excited to have more robust solution
- PIH: Often less than ideal approaches to ETL & analytics, excited for something that helps guide things forward
- KenyaEMR: Steve - historically has seen reporting solutions have all been suboptimal – e.g. having a ministry report running all night
- ITECH: Christina: Hoping to implement in Haiti. Tracy: secondary use of data at large scale; researcher of predictive analytics & clinical decision support
- Our prototype goals
- Clarify purpose as prototyping (it’s unknown what final tool/product will look like)
- Specific indicators
- Scalability (run on 1+ nodes)
- Goal is to create something useable soon (i.e., get to a working prototype people can actually use)
- Lessons learned from OMRS19:
- Common need for flattening encounters (e.g. people trying to analyze How many patients did we see where X happened?)
- Creating a table for every form - an idea from prototype approach that suggests how it will work to automatically produce e.g. a CSV for each form
- Lessons learned from BIRT & others:
- Our data model is constantly changing; the questions you want to answer are always new (nature of medical info - which test is done changes year to year)
- Need tooling that's at production level to not have to define our whole schema up front. Use standards & tooling conventions wherever possible.
- Need to echo standards so we don't have to build multiple aspects - tools coming to existence built on standards (e.g. expect to see more of this w/ FHIR). Want tooling we can support in 1-2 years.
- FHIR as (1) first intermediary step/data store w/ initial transforms, +/- (2) build your own extension as needed w/ transforms you need
- There will no doubt be efforts outside of OpenMRS to transform FHIR to OHDSI's common data model
- ITECH: working on prototyping way to pipeline data into a side-by-side HAPI FHIR store for q. OMRS instance - hope is to use some kind of ETL
- Bashir has been experimenting with extracting into FHIR schema
- Will need to discuss schema more!
- Leveraging recent community EIP work
- Debezium chosen as way to broadcast elements, create an outbound from OMRS to get data from
- Now need tool to help route messages (and well dev'd/designed, saves ++ dev time) - Apache Camel well-suited, but can't drop Camel on EIP side
- OMRS should be able to spit out FHIR messages out of the box. Until it can, need to identify the layer that does this and who's getting it done. Ideally FHIR subscription model is what OMRS should be able to do. So "if you need X data, subscribe to OMRS and FHIR model can generate for you". Mekom willing to support full-time developing ability for OMRS to support doing this.
- ETL tech layer should expect to receive FHIR data - not the job of the ETL pipeline. Extract FHIR and transform as needed from there.
- Need reliable event generating system. That's what the pipeline pulls from. (Right now in OMRS this is basically MySQL)
- Clarify purpose as prototyping (it’s unknown what final tool/product will look like)
- How often we meet
- Weekly
- First priorities:
- Requirements & what's getting built - ground in prototypes groups have already made
- One prototype every squad call? (20% of time on prototypes every week)
- Send doodle (or Slack poll) for ?Wednesday, next presenters
- Sprint structure
- Where we collaborate digitally
- We use Talk for discussions and decision-making (documenting decisions)
- We use Slack #etl to chat (and assume those discussions will never be seen again)
- Data environment
- Centralized server with unified sample dataset that we can use to do development and analysis
- Cloud vs On Premise
- Any other role clarification
2020-07-30: Focused discussion on PIH's ETL work
Attendees: allan kimaina Bashir Sadjad Ian Bacher Grace Potma Mike Seaton Mark Goodrich
- PIH's ETL infrastructure:
- https://github.com/PIH/petl
- Chose Pentaho because concern about need for other devs who understand more cutting edge tech if they chose a different option.
- This tool executes pipelines; Pentaho separates them. Analysts using PowerBI to create reports; don't write in SQL. PowerBI couldn't directly suck data from MySQL. Approach was crashing machines of end users; and it became clear that PowerBI was going to be what end users were using to review analytics. PIH added a MySQL to MS SQL-server bridge since PowerBI can consume data from SQL-server directly.
- Is the goal to calculate some fairly standard metrics or do they vary from site to site? They vary and there data analysts who are not SWEs but know how to use data, e.g., through SQL. They may have custom needs.
- Another source of variability is minor differences between different OpenMRS implementations.
- FHIR:
- Requiring FHIR would be a big concern because not useable/friendly enough for end-user Analysts.
- No way the users of their analytics tools would be able to write a query like this:
- But we need some middle schema anyways, can that middle schema be FHIR? Potentially, yes. It also depends on the adoption of things like SQL-on-FHIR.
- There is an agreement that if we want the middle layer to be flexible enough to do various analysis, its data model and queries will be inherently complex.
- The current main pain points:
- How to get data out of OMRS; currently it is through cron jobs that recreate data warehouse tables from scratch. Incremental support is definitely useful.
- Dealing with OMRS data model is not easy.
- Is the current PowerBI system work on a single machine or a cluster? How many patients and observations are we talking about?
- Yes, PowerBI runs on a single machine.
- One of PIH's bigger installations has ~400K patients and ~40M observations.
- People want to be able to drill down to actual data, so just providing the target metric is not enough.
2020-07-16: Identify considerations for squad success
Attendees: allan kimaina Bashir Sadjad Ian Bacher Jennifer Antilla Grace Potma
- Need for a separate non-MySQL platform?
- Might be fine when you have small, single sites; but when you want to do data analysis on all them, you need a data warehouse where a single MySQL approach won’t work
- Bashir developing things beyond MySQL already - but do we really need a non-MySQL-based solution?
- Work of squad could be just to write those scripts
- Aim: Not to be locked-in to MySQL. GSoC project working on support for Postgres b/c right now other groups having to install MySQL just to run on OMRS
- Unclear: How possible is it to have a solution that runs across different SQL servers? (SQL supposed to be a standard but reality is it gets implemented differently across multiple vendors → problem for OMRS)
- Posed these questions in Bashir’s FHIR Analytics Google Doc
- Calculations of concepts in background end up causing headaches - this ETL approach doesn’t scale @ Ampath; KenyaEMR have similar experience
- Takeaway: Not going to be a single MySQL approach, because this doesn’t scale and doesn't address the issues IN’s have already run into
- Final output and its usage
- People used to writing SQL - need a tech that someone in M&E/Data Science can simply write SQL to generate a report
- Requirement: Whatever we do, ppl need to be able to run SQL on the solution
- Spark? Hive? Others from Hadoop+?
- Small deployments (10’s of clinics) - should be easy for them to use in single processing environment (on device on location); shouldn’t assume everyone knows how to bring up a cluster w/ 10’s of nodes
- Output could be a MySQL DB
- Requirement: Whatever metric is required, there should be support to drill down further, all the way down to 1 record (easily able to go down to pt records)
- E.g. “Aggregate the # of pts with VL Suppression.” Ppl see # and say “this is an under/over report!”
- Ability to return to MySQL
- Requirement: It should be easy to use the data from within OMRS (exposing the data in OMRS should be easy)
- Quickest way is through MySQL. But exporting data back into MySQL can become a bottleneck
- Module could be the reporting module, tweaked to be able to work with this.
- Requirement: Data in warehouse should be de-identified
- Feature? Issue is compliance.
- Alternative: Access Management
- Deployment requirements
- MVP Requirement: Runs on single node
- MVP+ Requirement: Runs on multiple nodes
- Everything should just work regardless of how many VMs (single or 10’s) - does not require/assume cluster management. E.g. shouldn’t expose dataflow clusters to end users
- MVP Requirement: Provide simple notebook with examples on how to use, query, specific transformations
- Don’t assume ppl know how to run spark cluster or connect data to mySQL DB
- Others working on ETL: UW+I-TECH, Mekom, PIH, etc.
- I-TECH: Meeting w/ Jan & Tracy (to work on I-TECH’s ETL work)
- Mekom: DB Sync work - separate binary that syncs multiple OMRS deployments
- PIH: Mike & Deb & Mark re. How they’re using COVID19 as case study for ETL pipeline
- These are the ppl to regularly engage with when we set up squad (even if all they do is attend weekly squad meetings to give feedback & contribute)
- Team/work/processes etc.
- Clarify purpose as prototyping (it’s unknown what final tool/product will look like)
- E.g. weekly vs q2 weeks, with open collaboration session other week
- Sprint structure
- We use Talk to ____
- We use Slack to ____
- Centralized server with unified sample dataset that we can use to do development and analysis
- Cloud vs On Premise
- Requirements of external agencies - e.g. @ Google all OS forked repos must live under a Google Org (would hurt visibility)
- Bashir to f/u at Google.
- Intro of Technical Leads
- Our prototype goals
- How often we meet
- Where we collaborate digitally
- Data environment
- Any other role clarification
- Work tracking process (Bugs, tickets) while working towards prototype?
- How we consolidate our code, code review process & how we expect this to change over time; expectations for merge/release frequency
- Address nuances contributors are working with
- Decision: Best if everything we develop lives under OMRS.
- Time offering
- Rules of thumb we’ll follow for decision making
- For reference: Decision Making Playbook
- Who has decision making authority
- What to do when lack of consensus is blocking forward movement
- Champion sites (these would be the people who'd use our outputs when we release them)
- Main champion site at this point = Ampath b/c they have biggest DB (& Allan’s expertise!) - able to say “with a DB this size, we can run these obs and metrics successfully” so it should work for smaller sites
- Elevator pitch: Solution that shortens the time and improves the quality of using OMRS data in indicator reporting, reduces unplanned technical team member overtime, and makes it easy to drill down to patient-level data to confirm the numbers are correct.
DONE: Grace post announcement on Talk w/ Doodle; Grace combine requirements into Requirements page.