Data Integrity Module - 2.0 Design Overhaul
- Jeremy Keiper
- Burke Mamlin
Upcoming Design Changes
For various reasons, the fundamental storing of query results needs to change to a per-row-returned design. This requires linking a given integrity check to 0..n results, each identified by a unique identifier (i.e. one or more concatenated columns) and associated with metadata (e.g. dateCreated, status).
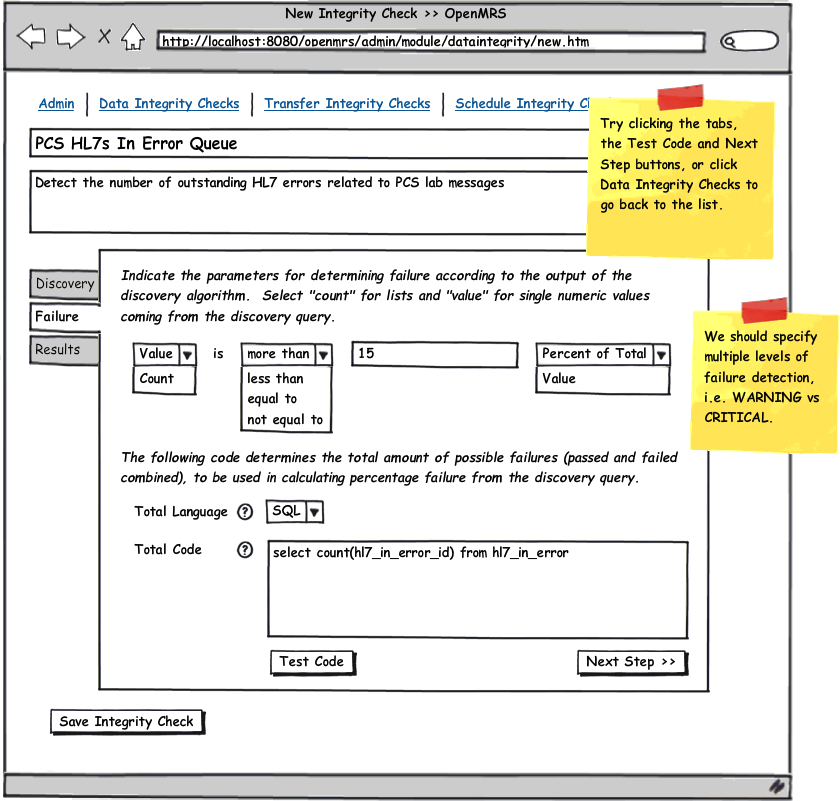
"Failure" has a wide range of meanings in the current implementation of the Data Integrity Module. In practice, failure is an indicator that the total amount of records returned breached a set threshold (usually zero). Additionally, there may be a desire to set multiple thresholds, such as "warning" and "critical".
UI Changes
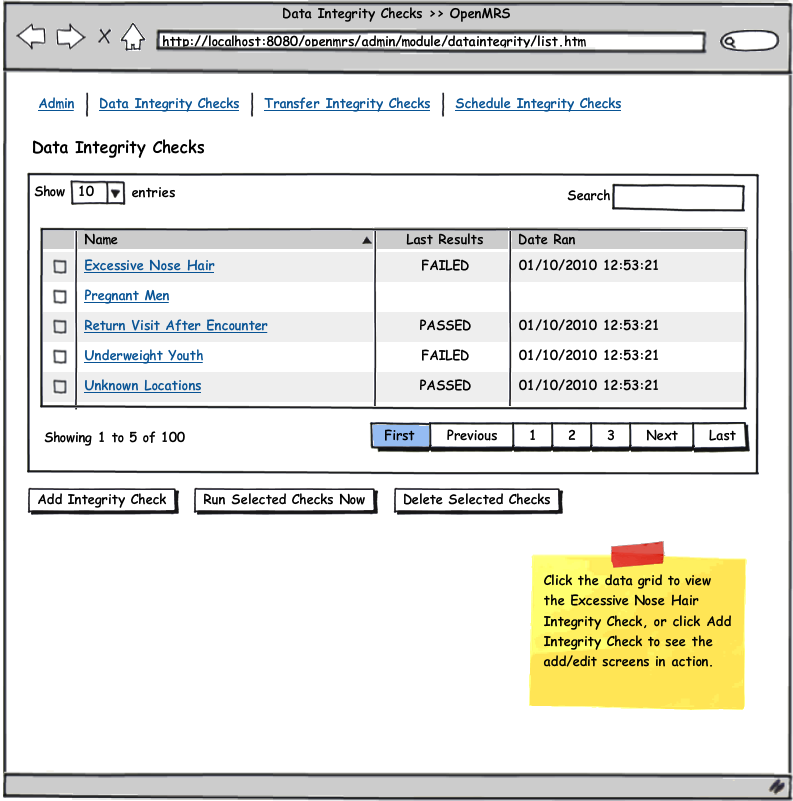
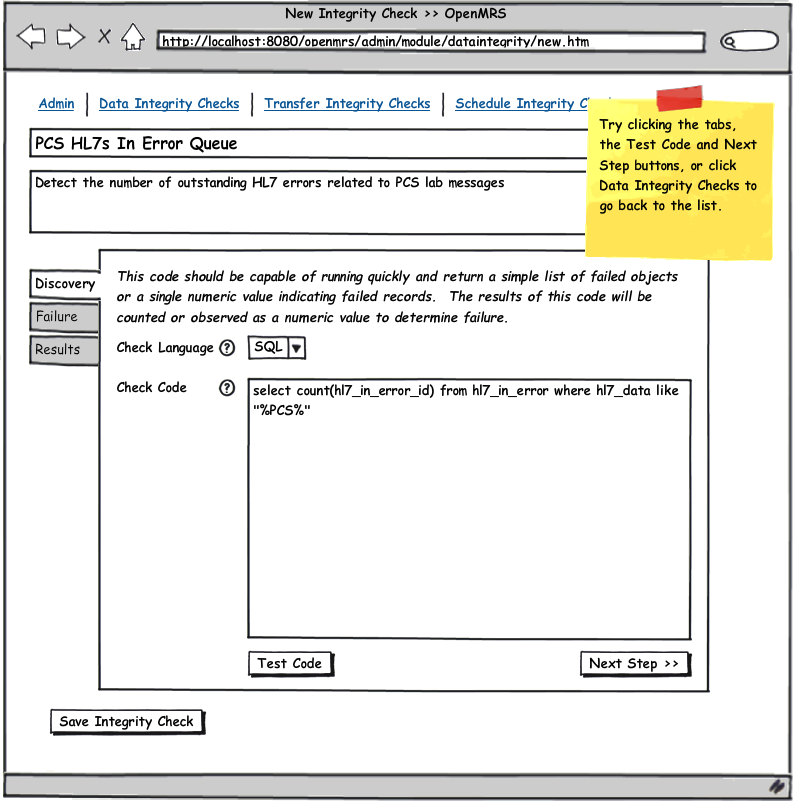
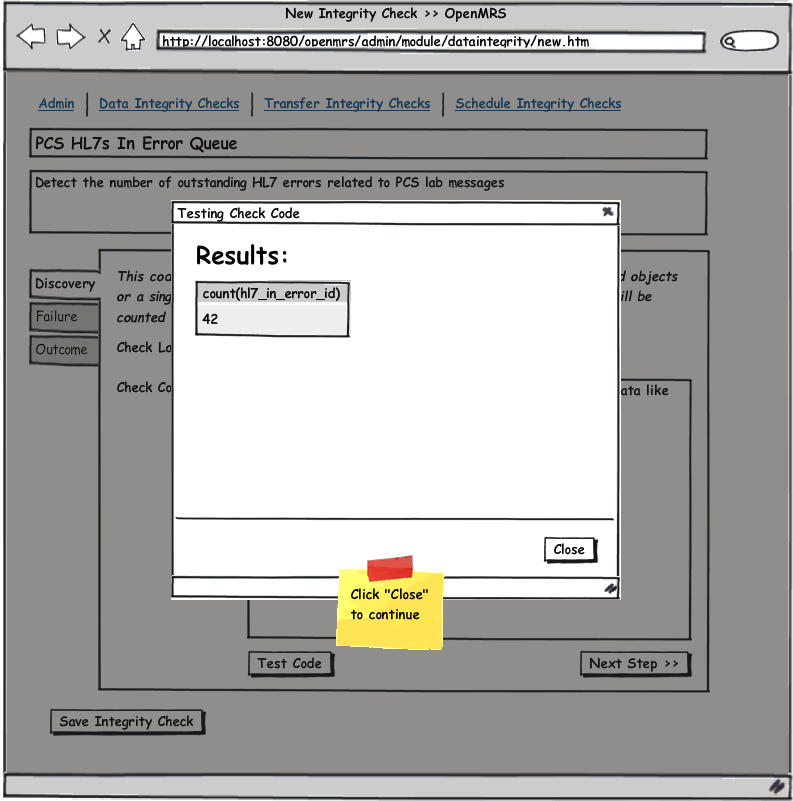
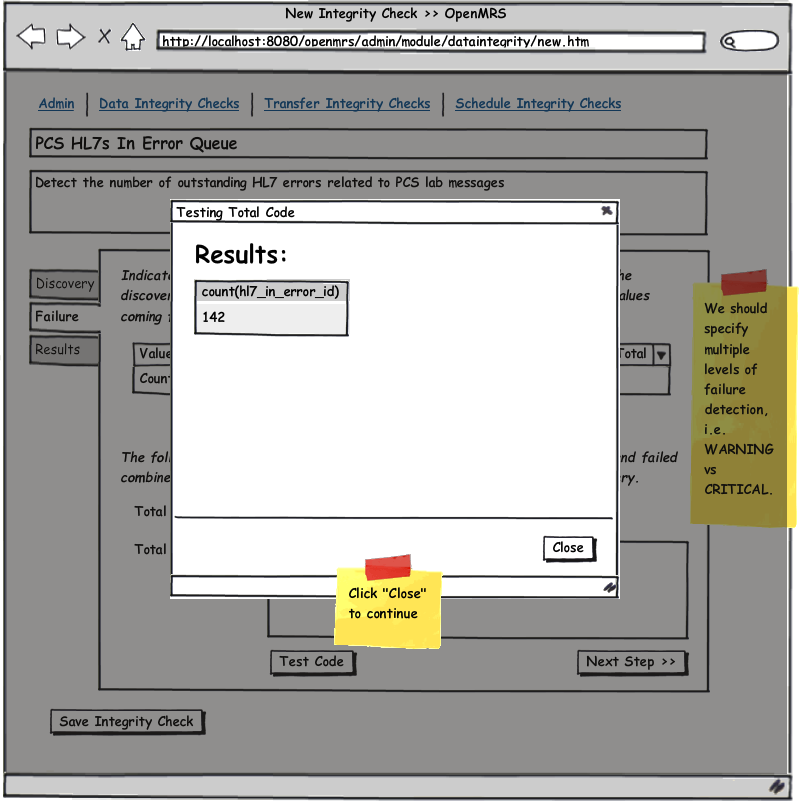
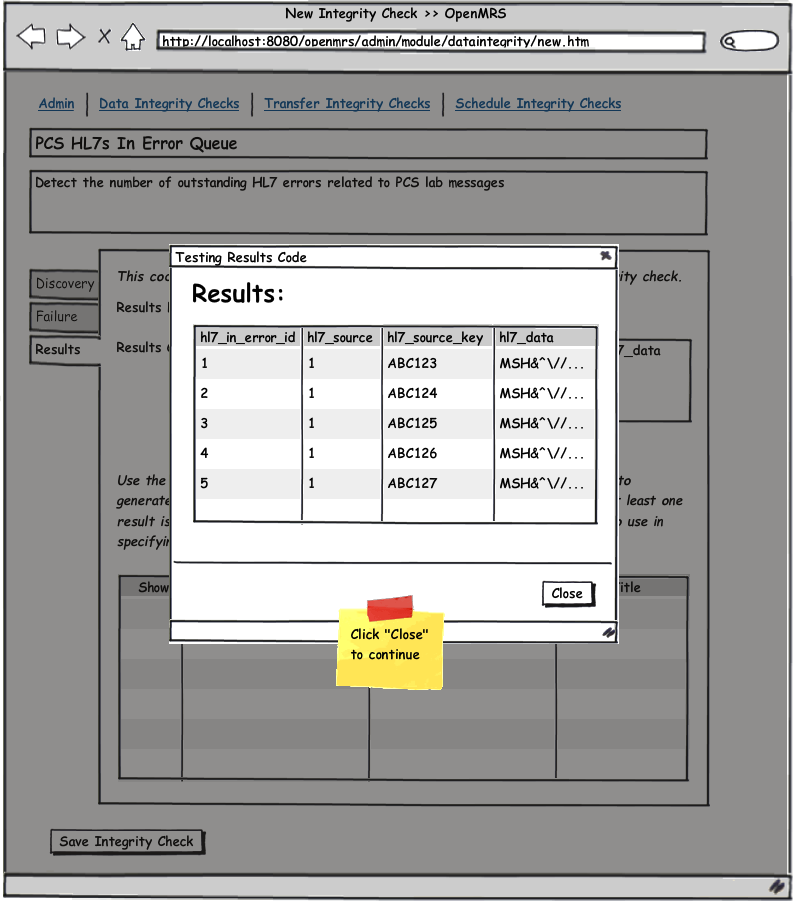
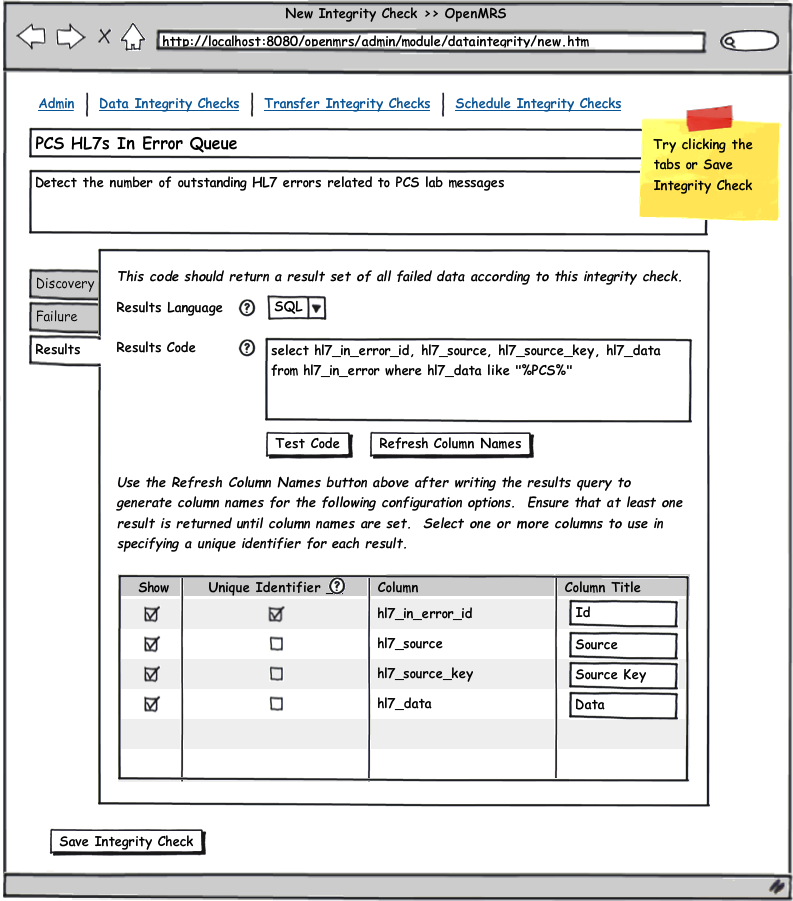
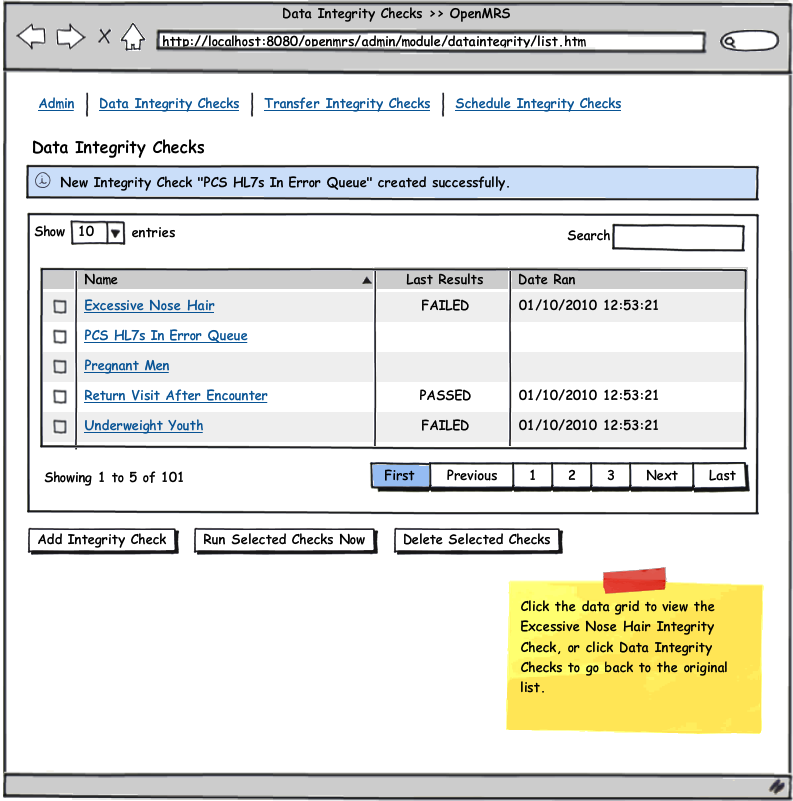
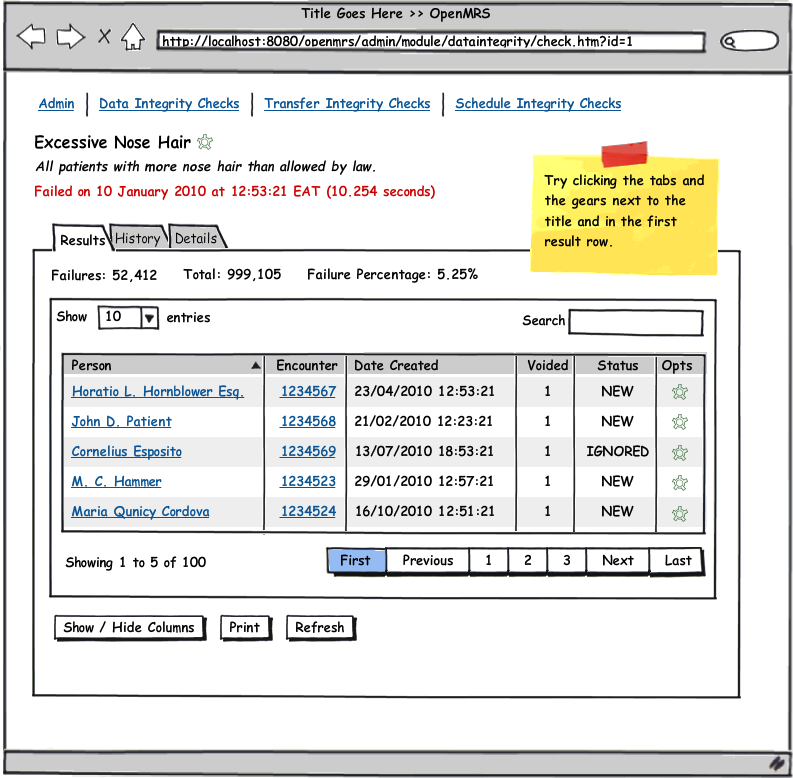
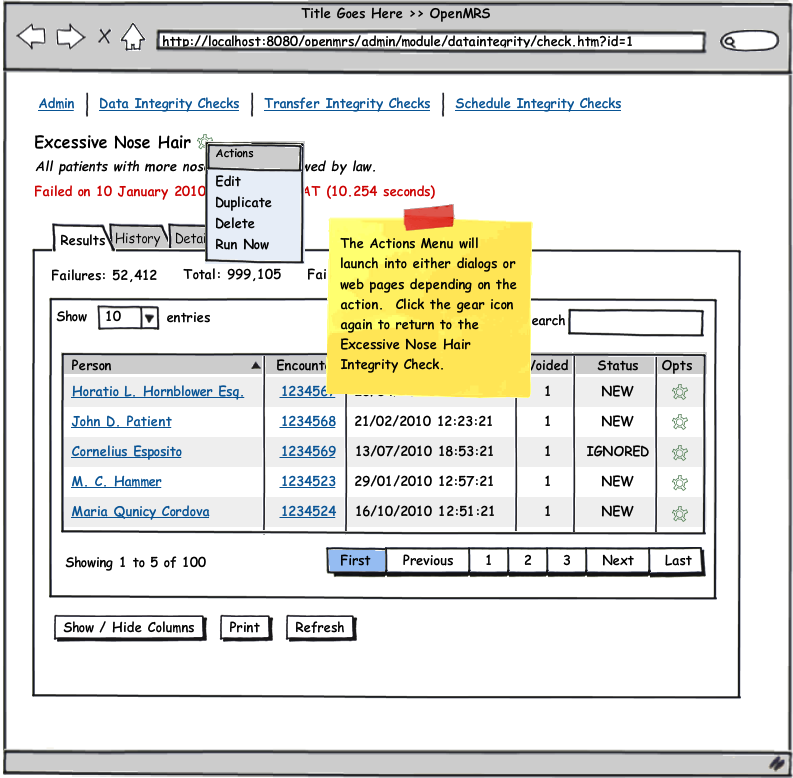
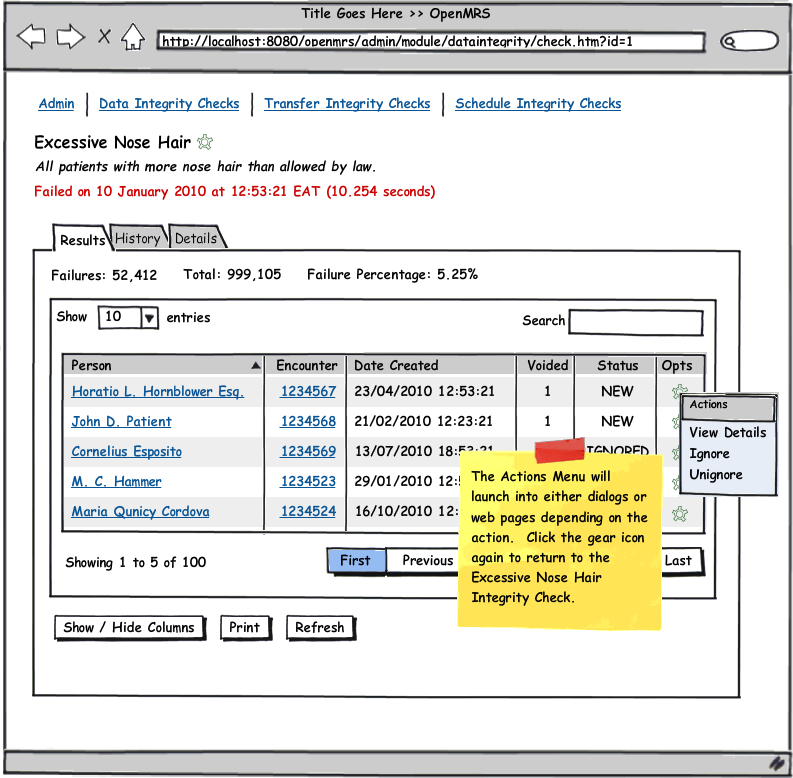
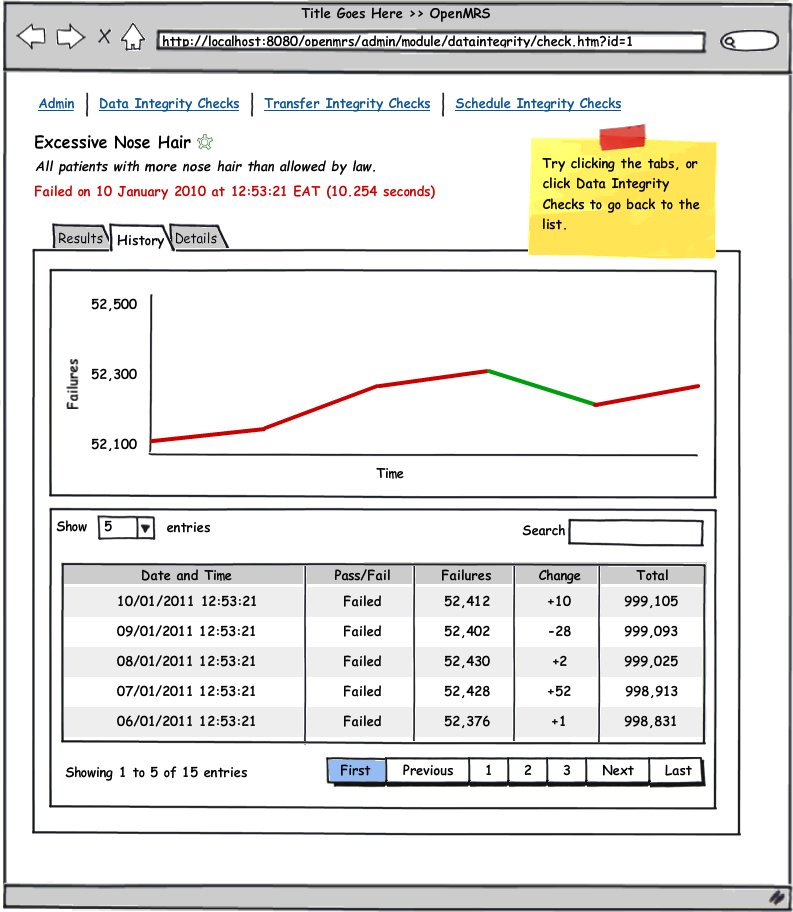
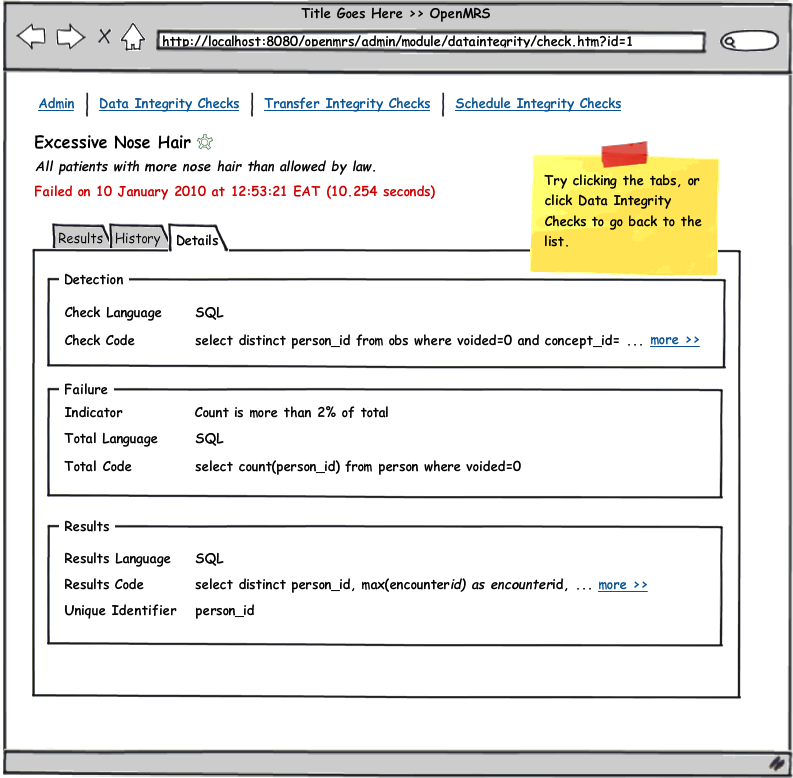
See the attached UI wireframe PDF or simply click on any image below for a clickable walk through.
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
Data Model Requirements
Each of the following data changes is required and may have UI consequences.
IntegrityCheck
An integrity check must define the column(s) used to define associated results' uniqueIdentifiers
Column labels will have to be stored in the integrity check definition, but can be potentially gleaned from a trail run
List<String> columns
"Failure" related changes require parameters for setting thresholds
minWarningminCritical
IntegrityCheckResults
An integrity check has 0..n results
A result is comprised of the following information:
uniqueIdentifierdata(serializedObject[])statusdateCreatedcreatordateUpdatedupdatedBy
IntegrityCheckRuns
An integrity check has 0..n runs
A run is comprised of the following information:
checkPassedfailureCountduration(in milliseconds)dateCreatedcreator
Integrity Check Processing Requirements
Instead of storing the entire result set from the check or repair query, Data Integrity will need to store individual rows. This means that we need a way to identify a given result in some unique fashion, so we can maintain some form of status on it. A unique identifier has to be extracted from each row. This will be a string, typically identified by one column in the results.
Query: select * from encounter where enc_datetime > date_created
In this situation, the encounter_id column can be specified as the unique id, since it will always refer to the same information.
Tickets
Design Diagrams
Original Software Requirements
This module began as a Google Summer of Code project in 2009. The following is the original requirements specification provided for the module.
The core requirement is an OpenMRS module which compiles and runs on existing OpenMRS implementations (1.4 and up). The main requirements of the module can be listed as follows.
Phase 1
Adding an admin page which lists actions that a user can take
Creating integrity checks for several cases:
Patients with no preferred identifier.
Patients with more than one preferred identifier.
Patients with no name.
Patient Identifiers with an incorrect check-digit.
Unused Concepts in the Concept Dictionary.
Adding a page which lists all integrity checks that can be run
Allow the user to customize the tests that needed to be run
Allow the user to fix errors which constitute to failed tests and re run the tests after the fixes are done
Phase 2
Extending the support for more integrity checks
Unused Field Objects for Forms.
Duplicate Field Objects for Forms.
Unused Locations
Encounters having no Observations.
Pregnant, male patients.
Patients who have a wrong encounter type
Implementing complex integrity tests
Adding a page which allows the user to run all tests at a stretch